训练技巧拾遗:重参数化、标签平滑与 Dropout
这篇收一些零散但好用的训练技巧:重参数化、权重 EMA、Shake-Shake、标签平滑和 Dropout。
重参数化(Reparameterization)
重参数化指的是:训练时给网络加一些额外的层或路径来辅助优化(让训练更顺、或防过拟合),测试时再把这些部分融合回原有结构。这样额外开销只在训练时产生,推理时融合完和原始结构没有任何区别,却能白赚一点精度。(BN 层的参数在测试时也能融进前面的卷积层,属于同一类思路。)三个代表作是 ACNet、RepVGG 和 RepMLP。
ACNet 在训练时把一个卷积层拆成三条路径(额外加 和 卷积,以及每条路径各自的 BN):
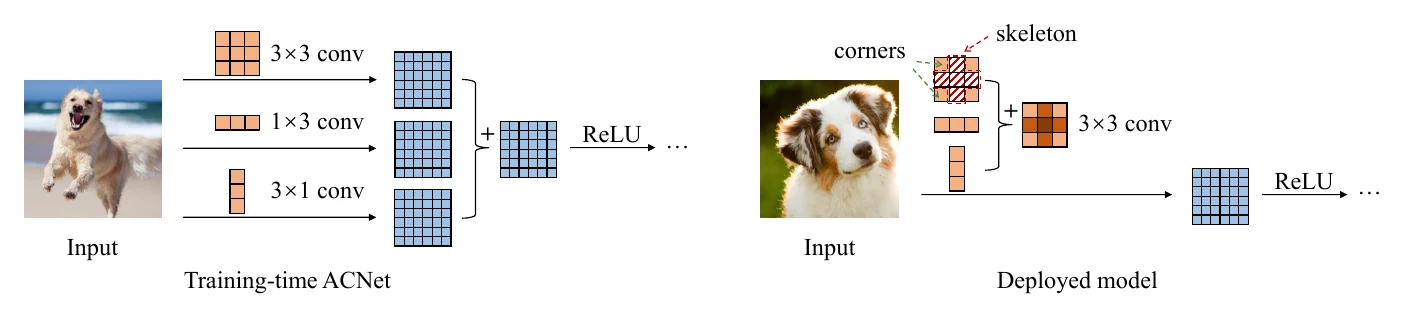
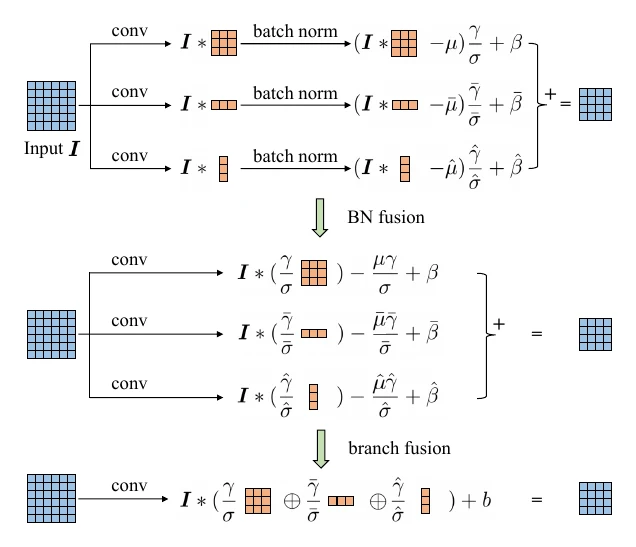
训练时每条路径各有参数,正常反向传播即可;测试时再把三条路径融合回原本的 卷积及其 BN——先把每条路径的 BN 融进它的卷积,再把三条路径的卷积参数加在一起,此时三条路径的前向传播就等价于一个卷积层。
RepVGG 用重参数化把 VGG 式的简洁结构训练到很高的精度——训练时用残差连接,比原始 VGG 更好训,精度能超过同算量的 ResNet;而推理时不需要残差连接,因此能用上 VGG 这种简洁结构带来的高推理效率。
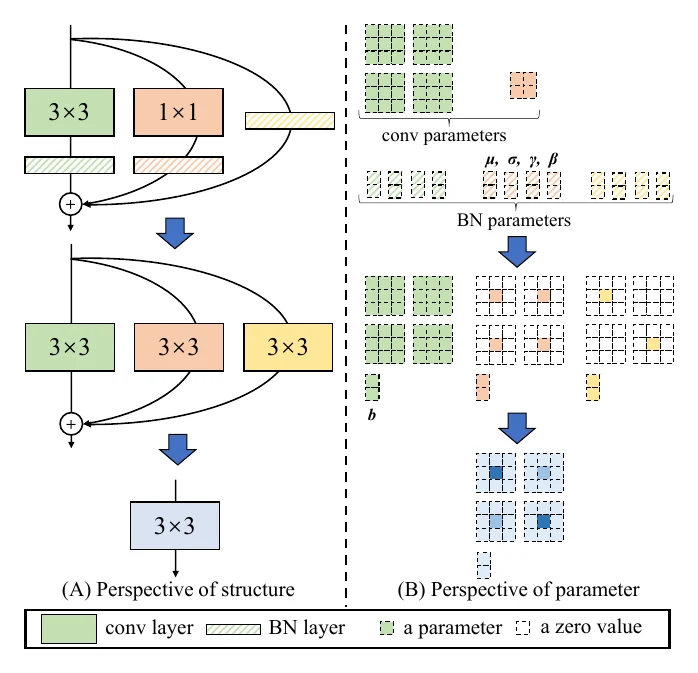
RepMLP 则把结构进一步从 VGG 简化到 MLP。
再往深里想:ACNet 和 RepVGG 训练时把一条支路拆成多条,而这些支路上都只有线性变换(只有卷积和 BN、没有激活函数),所以能直接融合在一起。理论上,任意多条只含线性变换的支路都能融合成一条——只是性能不一定因此变好。对全是卷积的支路,只要卷积核都不超过 ,就都能融进一个 卷积。再推广,卷积可以用 img2col + 矩阵乘实现,于是所有支路上的任意线性变换,都能融合成一条支路上的一次矩阵乘加——因此重参数化在 Transformer 这类结构里也可能有不错的应用空间。
权重 EMA
权重 EMA(Exponential Moving Average)在训练过程中额外维护一份权重的指数滑动平均,测试时用这份平滑后的权重而非最新权重。它几乎不增加训练成本,却常常带来更稳、更好的泛化。
Shake-Shake
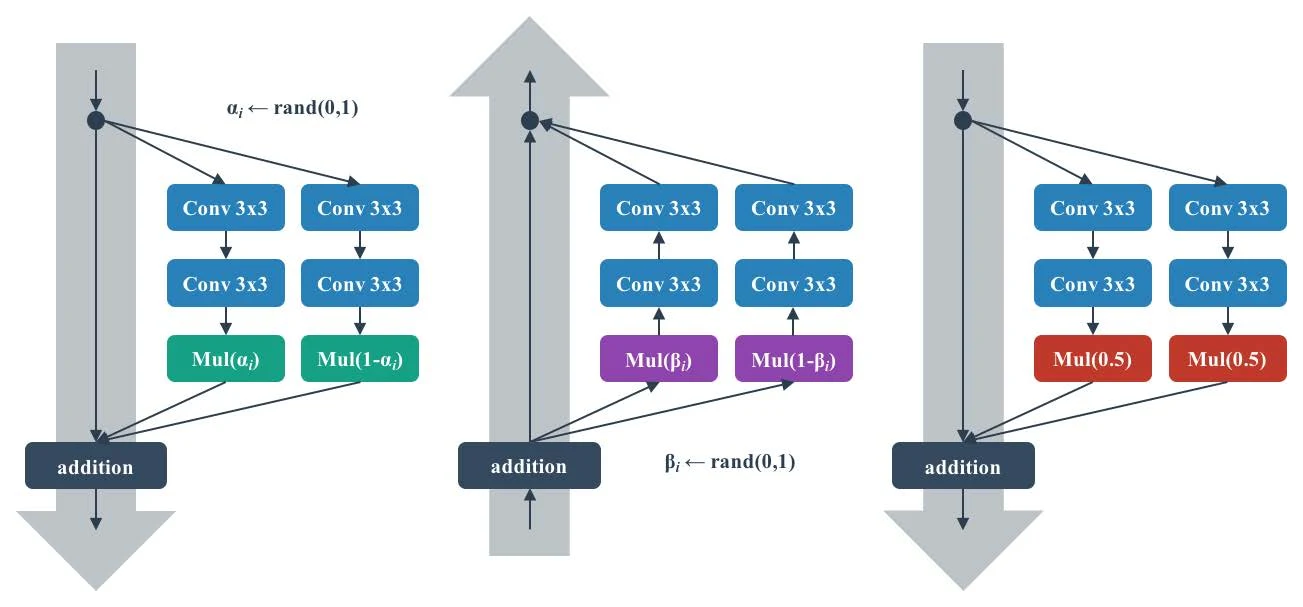
Shake-Shake 在训练时把一个分支随机拆成两部分来计算(每次前向都重新生成随机数 )。下图是它在残差连接上的应用:左为前向、中为反向、右为测试(此时 )。可以看出 Shake-Shake 会带来不小的额外计算开销。
标签平滑(Label Smoothing)
标签平滑顾名思义就是把标签”抹平”一点,实验表明这能提高泛化能力。分类常用的交叉熵损失为:
普通的 one-hot 标签是:
标签平滑把它改成(其中 是类别数, 是一个较小的平滑系数):
Dropout
Dropout 是常用的防过拟合手段,做法很简单:训练时,对输入 dropout 层的每个元素,按概率 把它丢弃(置零)。
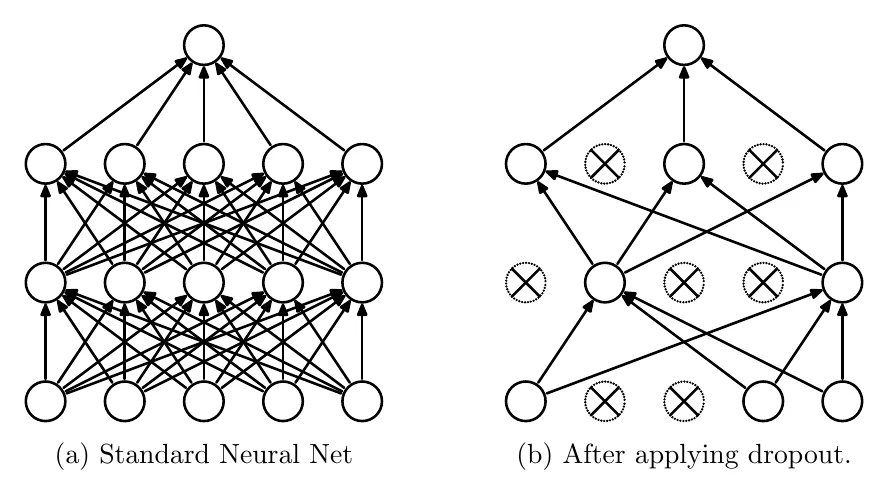
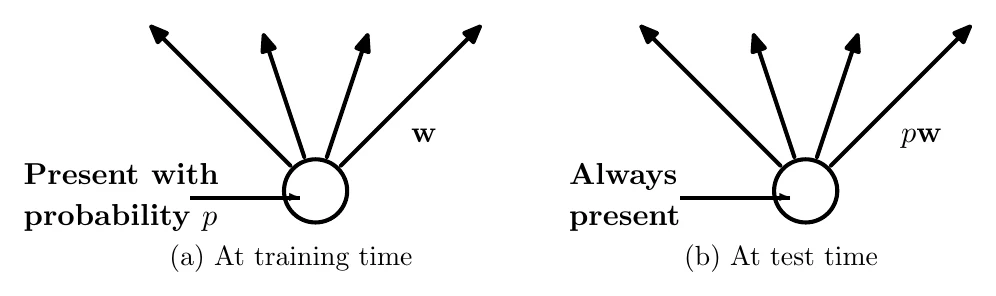
测试时则保留所有元素,这样训练相当于把单个网络近似成多个子网络的集成(ensemble)。另外测试时 dropout 层会把输入从 缩放为 ,目的是让每个元素在训练和测试时经过 dropout 层的输出有相同的期望值。
参考资料
- Ding, Xiaohan, et al. ACNet: Strengthening the Kernel Skeletons for Powerful CNN via Asymmetric Convolution Blocks. ICCV, 2019.
- Ding, Xiaohan, et al. RepVGG: Making VGG-style ConvNets Great Again. arXiv:2101.03697, 2021.
- Ding, Xiaohan, et al. RepMLP: Re-parameterizing Convolutions into Fully-connected Layers. arXiv:2105.01883, 2021.
- Gastaldi, Xavier. Shake-Shake Regularization. arXiv:1705.07485, 2017.
- Szegedy, Christian, et al. Rethinking the Inception Architecture for Computer Vision. CVPR, 2016.
- Srivastava, Nitish, et al. Dropout: A Simple Way to Prevent Neural Networks from Overfitting. JMLR, 2014.