A Training-Tricks Grab-bag: Reparameterization, Label Smoothing, Dropout
This post collects a few scattered but handy training tricks: reparameterization, weight EMA, Shake-Shake, label smoothing, and Dropout.
Reparameterization
Reparameterization means: during training, add extra layers or paths to help optimization (smoother training, or regularization), then fuse them back into the original structure at test time. The extra cost is only incurred during training; once fused, inference is identical to the original structure — but you bank a little extra accuracy. (Folding BN parameters into the preceding conv layer at test time is the same idea.) The three flagship works are ACNet, RepVGG, and RepMLP.
ACNet splits one conv layer into three paths during training (adding and convolutions, each with its own BN):
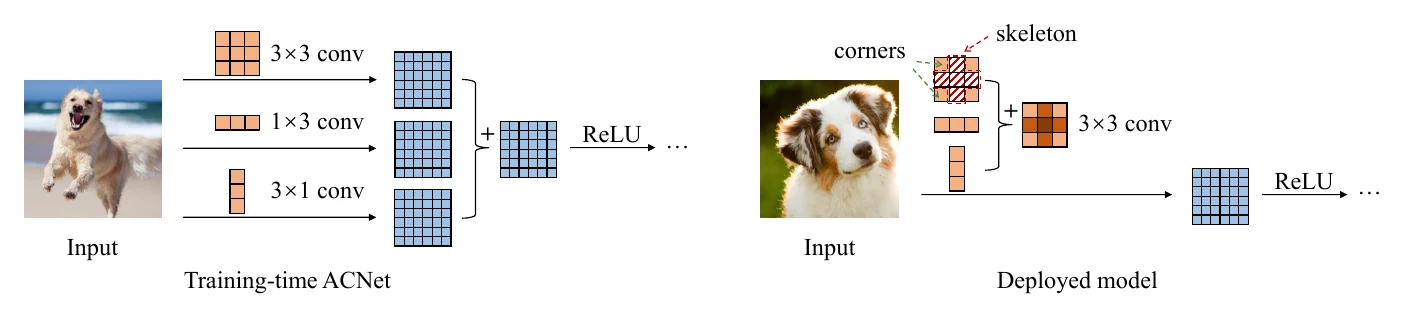
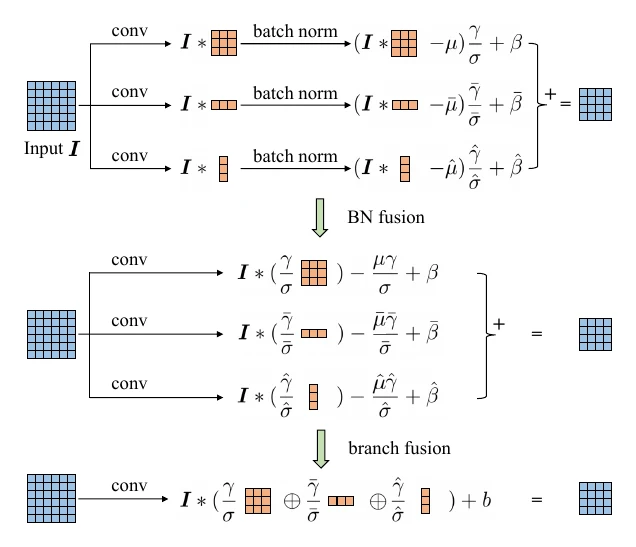
Each path has its own parameters and trains by ordinary backprop; at test time the three paths fuse back into the original conv and its BN — first fold each path’s BN into its conv, then sum the three convs’ parameters, so the three-path forward pass becomes equivalent to a single conv layer.
RepVGG uses reparameterization to train a clean, VGG-style structure to high accuracy — it uses residual connections during training (easier to train than plain VGG, beating same-FLOPs ResNet on accuracy) but drops them at inference, so it gets the high inference efficiency of a clean VGG-style structure.
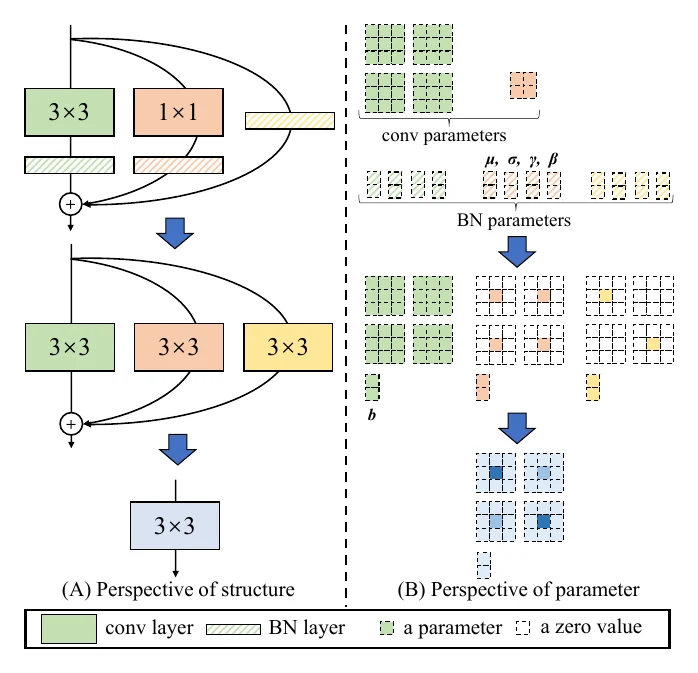
RepMLP simplifies the structure further, from RepVGG’s VGG style down to an MLP.
Going deeper: ACNet and RepVGG split one branch into several during training, and those branches contain only linear transforms (just conv and BN, no activations), so they fuse directly. In principle any number of purely linear branches can fuse into one — though performance won’t necessarily improve. For all-conv branches, as long as the kernels are no larger than , they all fuse into one kernel. Generalizing, convolution can be implemented via img2col plus matrix multiply, so any linear transforms across all branches fuse into a single matrix multiply-add on one branch — which is why reparameterization may apply nicely to Transformer-like structures too.
Weight EMA
Weight EMA (Exponential Moving Average) maintains an exponential moving average of the weights during training and uses those averaged weights at test time instead of the latest ones. It adds almost no training cost yet often yields steadier, better generalization.
Shake-Shake
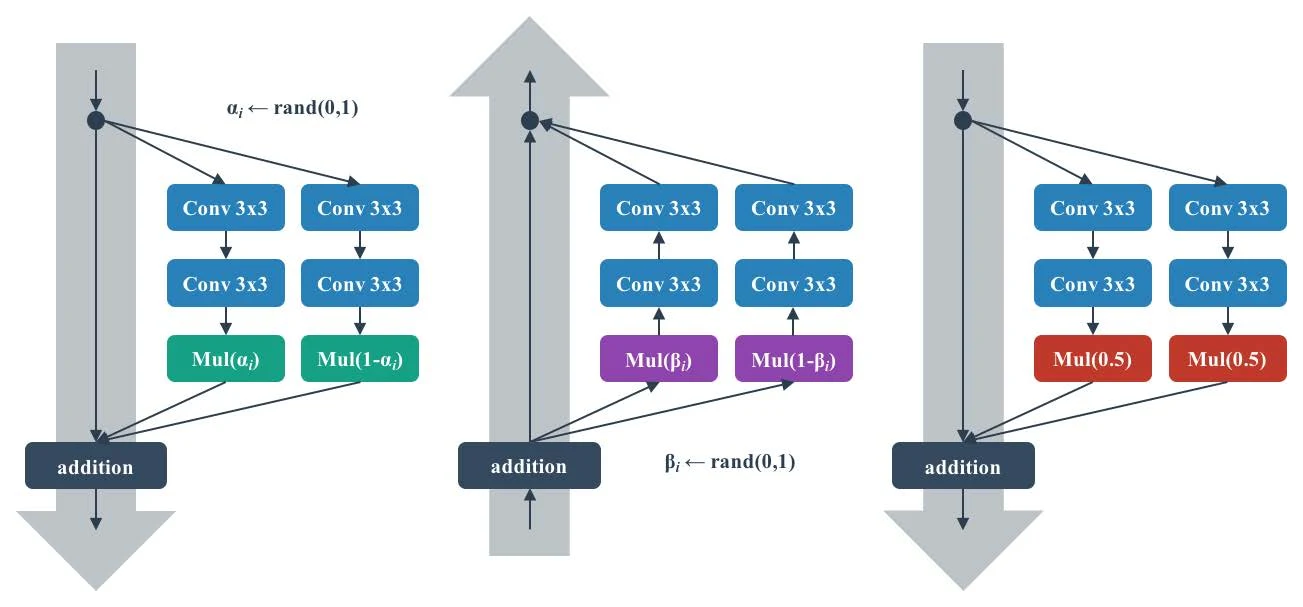
Shake-Shake randomly splits a branch into two parts during training (re-sampling a random on each forward pass). Below is its application to residual connections: left is the forward pass, center the backward, right test time (where ). As you can see, Shake-Shake adds noticeable extra compute.
Label smoothing
Label smoothing, as the name says, “smooths” the labels; experiments show it improves generalization. The cross-entropy loss used for classification is:
An ordinary one-hot label is:
Label smoothing changes it to (where is the number of classes and a small smoothing coefficient):
Dropout
Dropout is a common way to fight overfitting, and it’s simple: during training, each element fed into the dropout layer is dropped (zeroed) with probability .
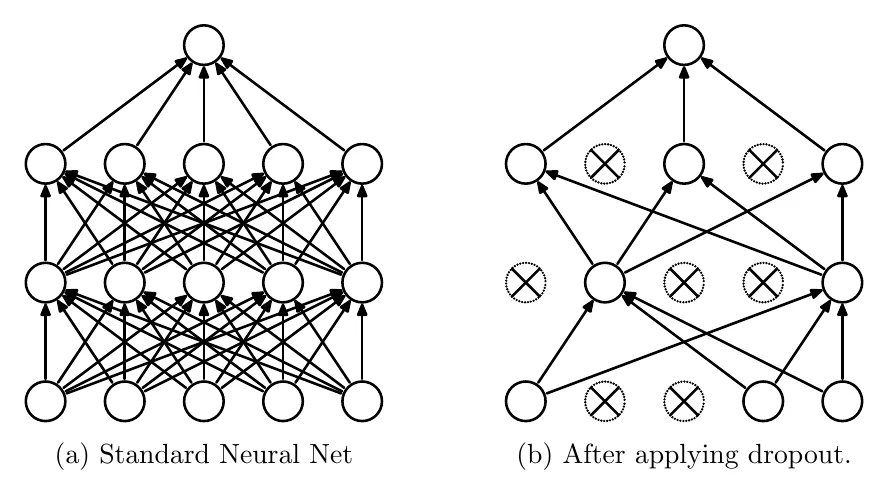
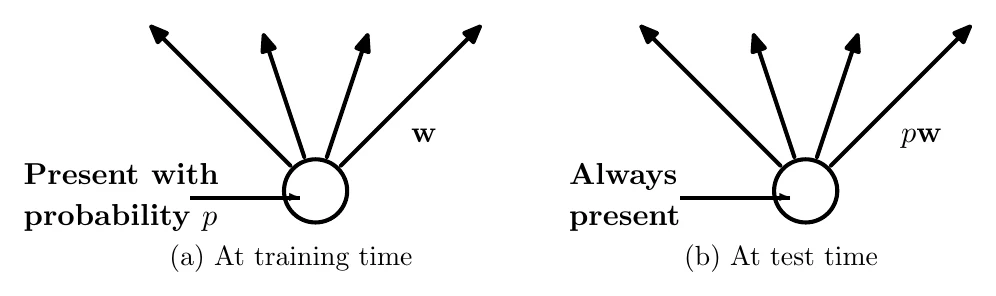
At test time all elements are kept, so training effectively approximates a single network as an ensemble of many sub-networks. The dropout layer also scales the input from to at test time, so each element has the same expected output through the dropout layer in training and testing.
References
- Ding, Xiaohan, et al. ACNet: Strengthening the Kernel Skeletons for Powerful CNN via Asymmetric Convolution Blocks. ICCV, 2019.
- Ding, Xiaohan, et al. RepVGG: Making VGG-style ConvNets Great Again. arXiv:2101.03697, 2021.
- Ding, Xiaohan, et al. RepMLP: Re-parameterizing Convolutions into Fully-connected Layers. arXiv:2105.01883, 2021.
- Gastaldi, Xavier. Shake-Shake Regularization. arXiv:1705.07485, 2017.
- Szegedy, Christian, et al. Rethinking the Inception Architecture for Computer Vision. CVPR, 2016.
- Srivastava, Nitish, et al. Dropout: A Simple Way to Prevent Neural Networks from Overfitting. JMLR, 2014.