类别不平衡怎么办:重采样、加权与集成
数据类别不平衡是实际应用里很常见的一类问题——现实场景的数据不会像公开数据集那样高质量,很可能正负样本数量极度悬殊。处理类别不平衡主要有三类方法:重采样(Resampling)、权重平衡(Weight balancing) 和 集成(Ensembles)。
重采样
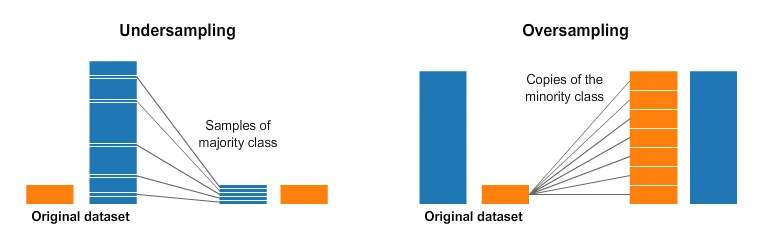
重采样有两种方向:对样本多的类别欠采样(undersampling),或对样本少的类别过采样(oversampling)。
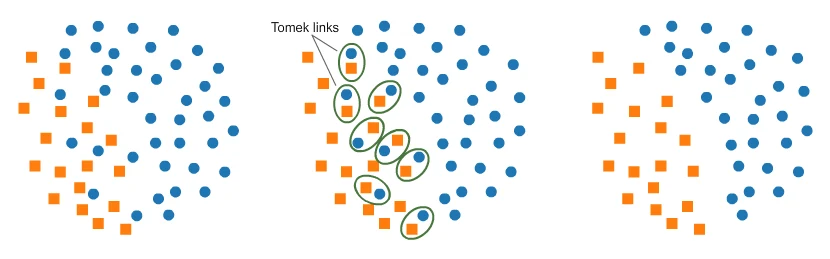
欠采样的一个经典算法是 Tomek Links:在多数类里找到那些与少数类样本最接近的样本,把它们移除,从而让决策边界更清晰。但这招不一定有效——它也可能抹掉一些细微的决策边界,适得其反。
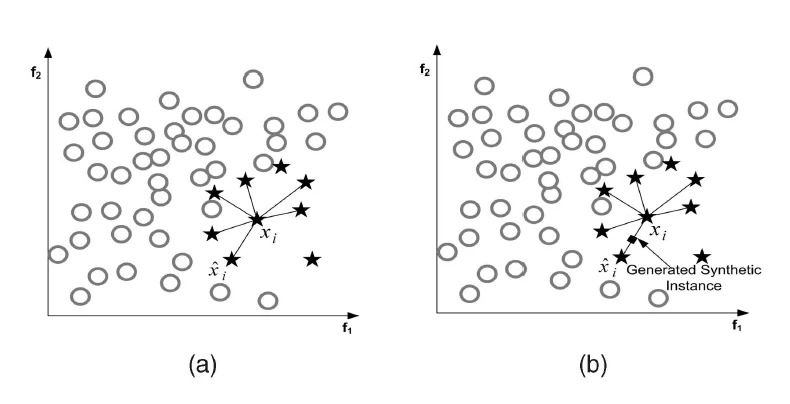
过采样的一个经典算法是 SMOTE:先算少数类中某个样本 的 K 近邻,从这 K 个近邻里随机选一个 ,再在 和 的连线上随机生成新样本;不断循环直到生成足够数量的新样本。
权重平衡
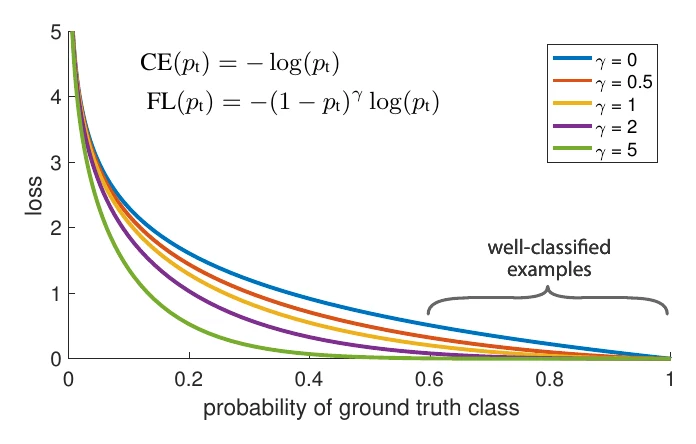
另一类方法是给不同类别的样本赋予不同权重,代表作是 Focal Loss:
其中 负责正负样本不均衡——给正负样本的损失赋不同权重; 负责难易样本不均衡—— 调得越大,置信度高的”简单样本”损失越小,损失函数就会更聚焦于难分的”复杂样本”。
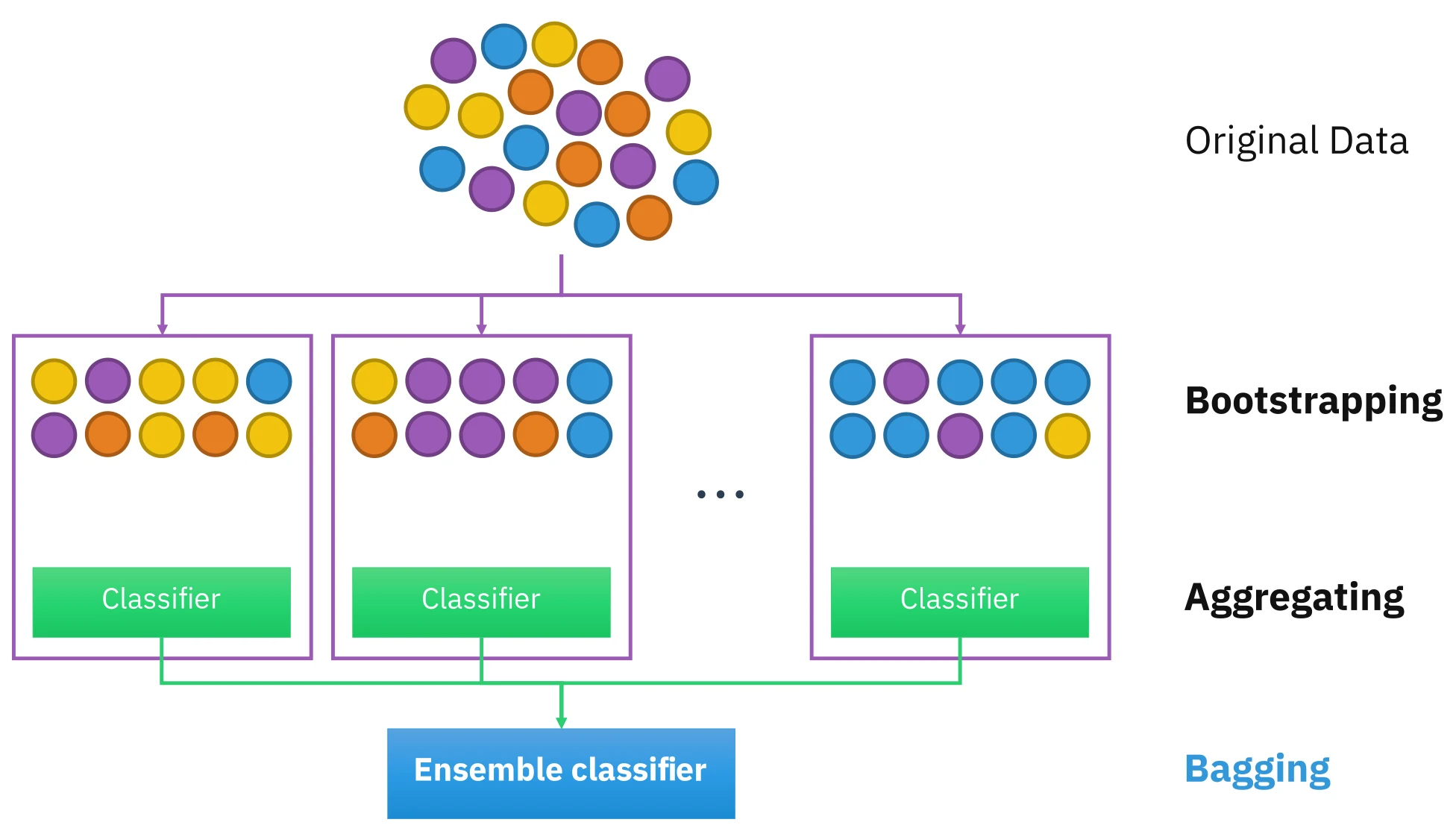
集成
还有一类是集成学习(Ensemble)。常见的 Bagging(bootstrap aggregating)采样出不同的数据子集训练多个分类器,再对结果投票,取得票最高的作为最终结果——多个弱分类器的组合往往比单个更稳健。
参考资料
- He, Haibo, Ma, Yunqian. Imbalanced Learning: Foundations, Algorithms, and Applications. Wiley, 2013.
- Chawla, Nitesh V., et al. SMOTE: Synthetic Minority Over-sampling Technique. JAIR, 2002.
- Lin, Tsung-Yi, et al. Focal Loss for Dense Object Detection. ICCV, 2017.