Dealing with Class Imbalance: Resampling, Weighting, Ensembles
Class imbalance is a common problem in practice — real-world data isn’t as clean as a public dataset, and the positive/negative counts are often wildly skewed. There are three families of fixes: resampling, weight balancing, and ensembles.
Resampling
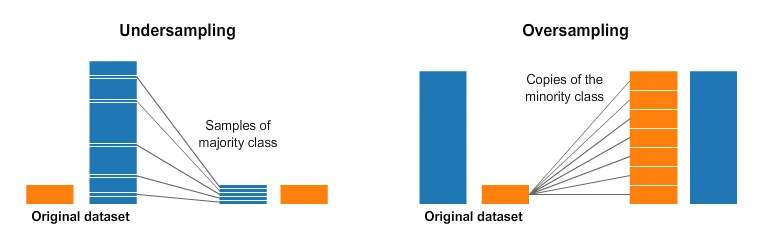
Resampling goes in two directions: undersample the majority class, or oversample the minority class.
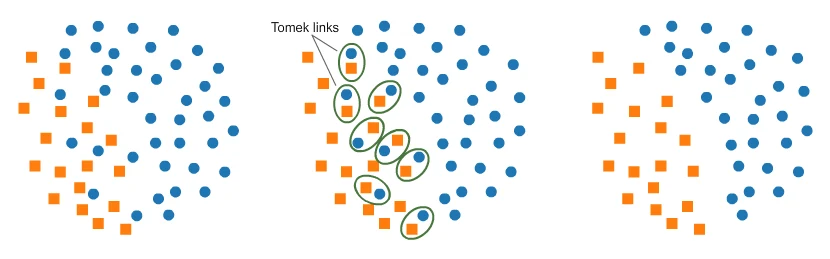
A classic undersampling algorithm is Tomek Links: find the majority-class samples closest to the minority class and remove them, sharpening the decision boundary. But it doesn’t always help — it can also erase subtle boundaries and backfire.
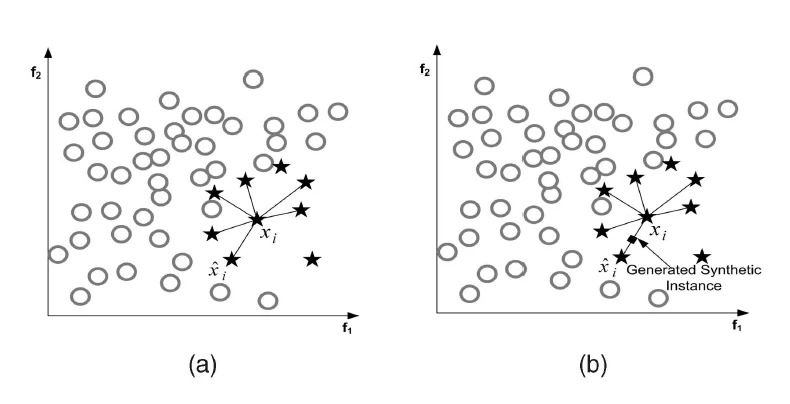
A classic oversampling algorithm is SMOTE: compute the K nearest neighbors of a minority-class sample , randomly pick one neighbor , and synthesize a new sample on the line between and ; repeat until enough new samples exist.
Weight balancing
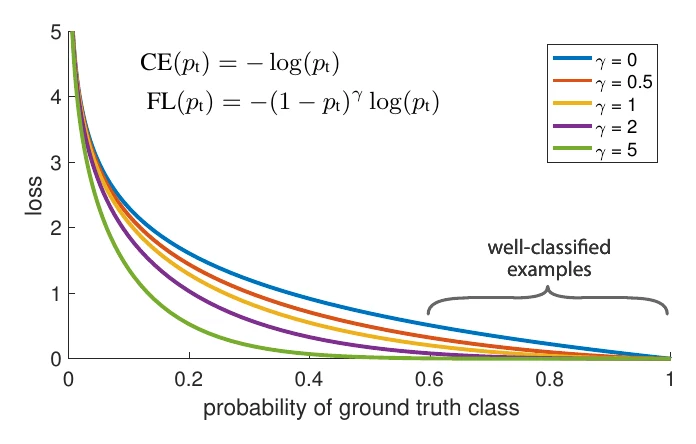
Another family weights samples by class, the flagship being Focal Loss:
Here handles positive/negative imbalance — different loss weights for positives and negatives — while handles easy/hard imbalance: the larger , the more the loss of high-confidence “easy” samples is suppressed, focusing the loss on the hard, “difficult” ones.
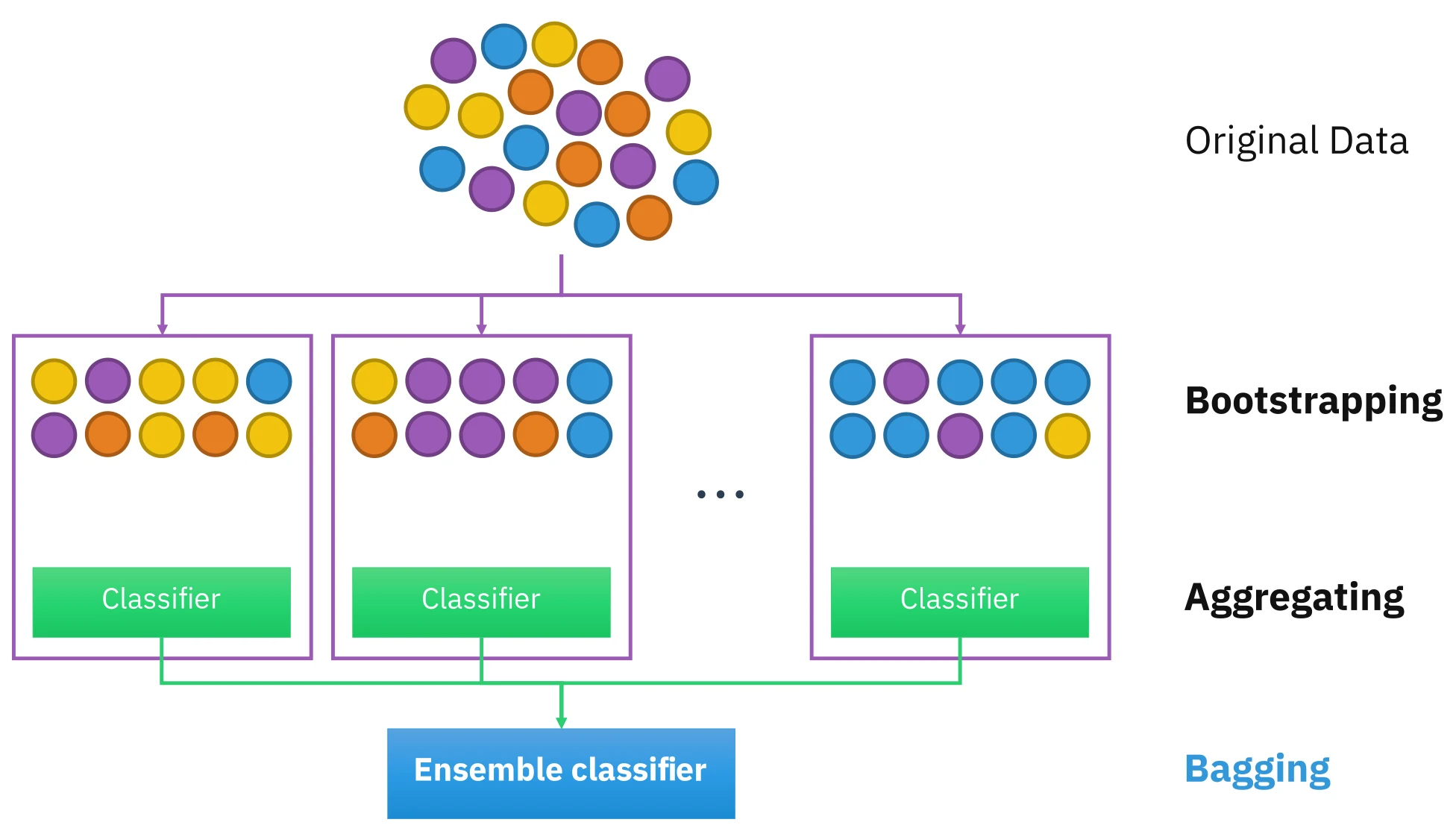
Ensembles
A third family is ensemble learning. The common Bagging (bootstrap aggregating) trains several classifiers on different sampled subsets of the data, then votes — a combination of weak classifiers is often more robust than any single one.
References
- He, Haibo, Ma, Yunqian. Imbalanced Learning: Foundations, Algorithms, and Applications. Wiley, 2013.
- Chawla, Nitesh V., et al. SMOTE: Synthetic Minority Over-sampling Technique. JAIR, 2002.
- Lin, Tsung-Yi, et al. Focal Loss for Dense Object Detection. ICCV, 2017.