怎么衡量一个神经网络的「好」与「快」
做模型优化,第一步往往不是动手改网络,而是想清楚一件事:我到底在优化什么,又怎么知道它变好了。 有句话说得好——If you can not measure it, you can not improve it。所以在谈任何加速、压缩之前,先得把”性能”这个词拆开。
一个神经网络的性能可以分成两条相互独立的线:
- 面向任务的性能:模型在它要解决的任务上做得有多好,比如分类准确率、检测的 mAP。
- 面向效率的性能:模型跑起来要花多少代价,包括时间(时延)和空间(内存)。
我们的目标,是在这两个维度上同时把模型往前推。下面分别来看。
面向任务的性能指标
卷积神经网络(CNN)的应用大多落在计算机视觉上,这里挑几类最常见的任务——图像分类、目标检测、语义分割、超分辨率——看看它们各自用什么指标。
分类分单标签和多标签两种场景。单标签分类一般看 Top-1 和 Top-5 准确率:都是”分类正确的样本数 / 总样本数”,区别在于 Top-1 要求模型输出概率最大的类别与标签一致,Top-5 则只要概率最高的前五个类别里有一个命中即可。但准确率本身不可导,没法直接拿来当优化目标,单标签分类通常用交叉熵损失:
其中 是输出的概率向量(维度等于类别数), 是标签类别, 是各类别的权重。多标签分类则常把每个标签看作一个二分类问题,最后把所有标签上的损失求和或求平均归约成一个数。以求平均、总类别数为 为例:
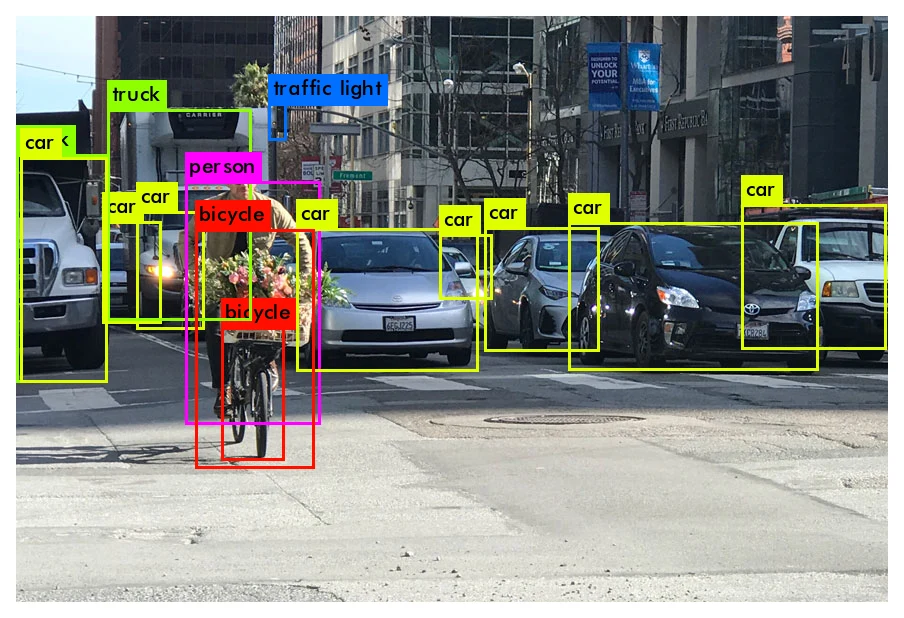
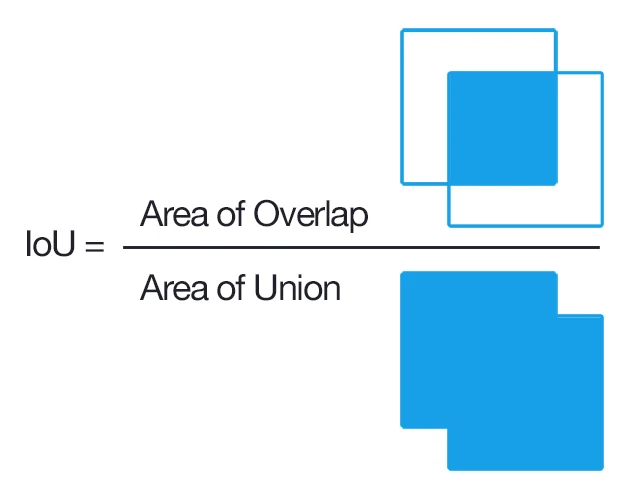
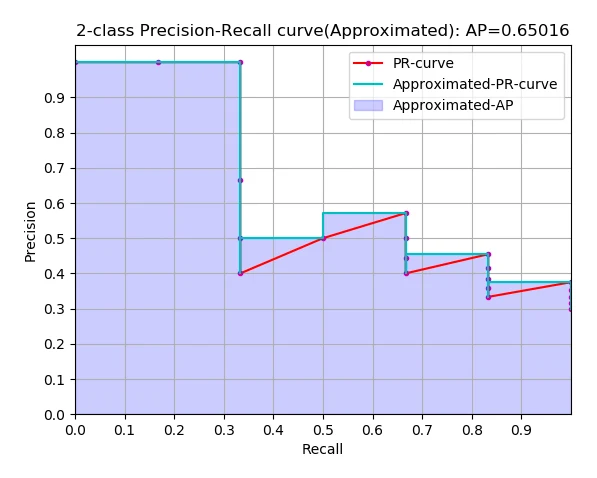
目标检测最常用的指标是 mAP(mean Average Precision)。它由各个类别的 AP(Average Precision)取平均得到,而每个类别的 AP 等于该类别 PR 曲线(Precision-Recall Curve)下方的面积。算法大致是:模型在整个数据集上预测出一批检测框后,对某个具体类别,先取出该类别在所有图片上的全部预测框,按置信度从高到低排序;再依次和标签框(ground truth)比对,如果预测框与某个标签框的 IoU(Intersection over Union)超过阈值(通常取 0.5),就记为 TP(True Positive),否则记为 FP(False Positive),并把该标签框标记为已检测、不再参与后续匹配;通过设定不同的置信度阈值,可以得到一系列 TP/FP,进而算出一系列精确率和召回率:
以召回率为横轴、精确率为纵轴描点并插值,就得到 PR 曲线,曲线下面积即为 AP。
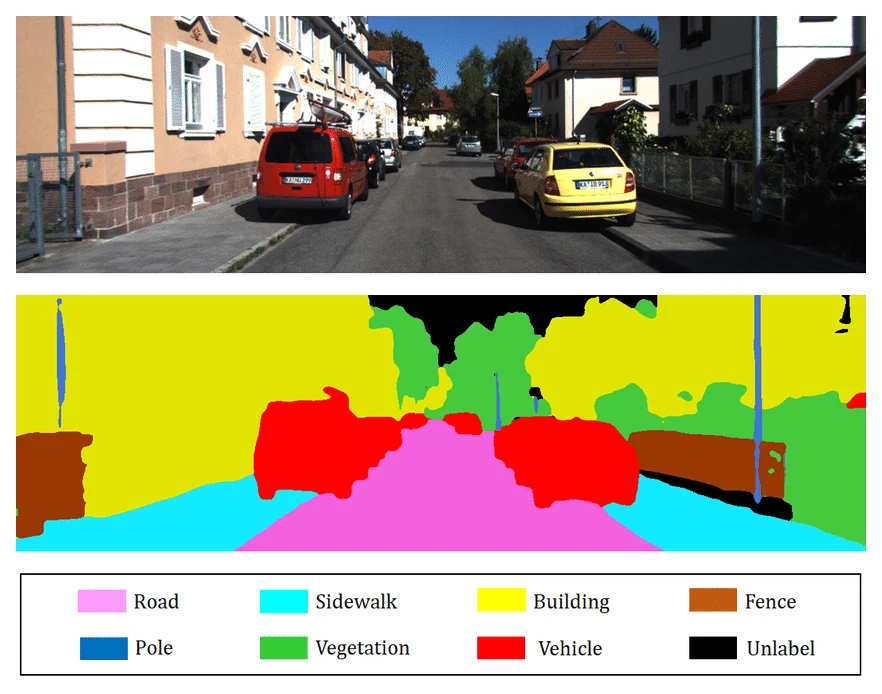
语义分割常用 mIoU(mean Intersection over Union):和检测类似,在每个类别上分别计算 IoU(算法同上图),再求平均。
超分辨率、图像修复、图像压缩等任务常用峰值信噪比 PSNR(Peak Signal to Noise Ratio)。PSNR 越高,代表压缩/复原后的图像与原图误差越小,图像压缩中典型值在 30dB 到 50dB 之间:
面向效率的性能
效率这条线分两个方面:时间上的和空间上的。因为网络训练只做一次,部署之后反复跑的是推理,所以这里主要讨论推理过程中的效率(训练过程本身的加速是另一个话题)。
时间:时延、FLOPs 与它的局限
时间上的效率主要指推理时延(latency)——做一次前向传播要花多久。时延和三件事有关:模型本身、软件实现、硬件平台。测量时这三者都会显著影响结果,所以面向模型做优化时,必须在一套稳定的软硬件环境里测,排除其他干扰:用同一个 docker 镜像、同一块硬件、测之前对 cache 做预热(warmup)、多组取平均,等等。
但不同研究者很难在统一的软硬件平台上对比,于是常用一个间接指标 FLOPs(floating point operations,有些论文也叫 Mult-Adds)来替代时延。CNN 的 FLOPs 主要集中在卷积层和全连接层。卷积层:
其中 是输出特征图的长宽, 是输入/输出通道数, 是卷积核大小。全连接层:
为输入/输出维度。算某个网络的 FLOPs 已有现成工具,比如基于 PyTorch 的 torchprofile。
间接指标自然有局限:它算不进访存开销,也算不进并行化、高性能算子实现带来的提速。为了看清这个差距,我对一批经典网络分别测了 FLOPs 和统一平台上的 GPU 时延,并统计了卷积、矩阵相乘(gemm)和其他操作各自的 FLOPs/时延占比:
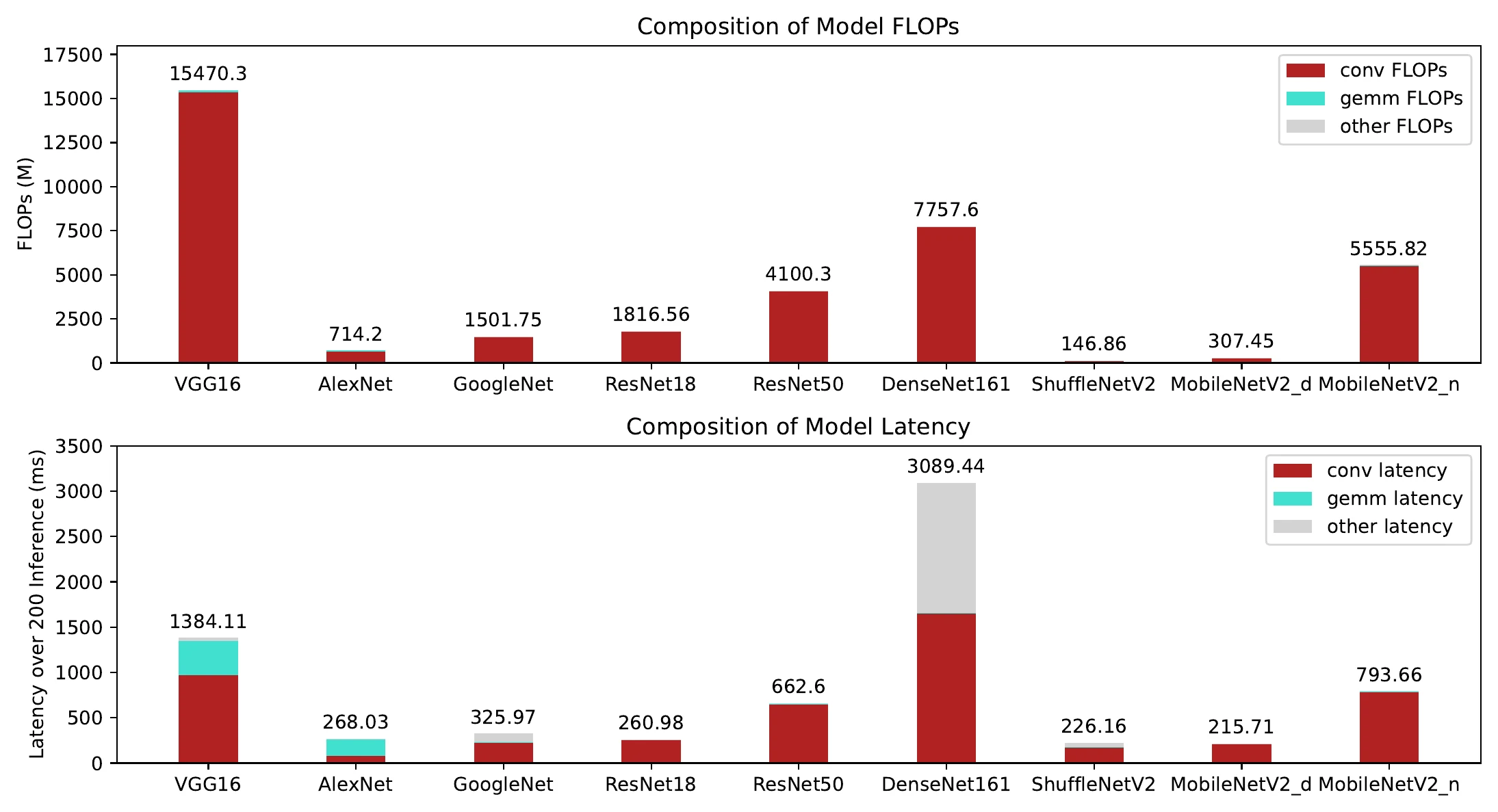
整体上 FLOPs 与时延正相关,但有几个扎眼的例外,最典型的是 VGG16 与 DenseNet161 反了。VGG16 有 15470.3M FLOPs、1384.11ms 的 GPU 时延(转成 TensorRT 预热后连续 200 次推理的总时间);DenseNet161 只有 7757.6M FLOPs——FLOPs 仅为 VGG16 的一半,时延却超过它两倍。原因在于 FLOPs 只算了计算量,没算访存。DenseNet161 里有大量 Copy 操作(转 TensorRT 后约为卷积操作的 10 倍),这些开销完全不反映在 FLOPs 上。即便扣掉 Copy,DenseNet161 仍略慢于 VGG16:它有 160 个卷积操作,而 VGG16 只有 13 个——VGG16 的 FLOPs 更大,卷积操作数却少得多,访存开销小,反而更快。ShuffleNetV2 也类似,其中的 Split、Reshape、Transpose 占了约 20% 的时间,但都不体现在 FLOPs 上。
还有个值得注意的现象:AlexNet 里 gemm 操作的 FLOPs 占比只有 8.2%,时延占比却高达 67.7%(可惜实验跑在 docker 容器里,没权限访问 NVIDIA GPU Performance Counters,没法对 kernel 进一步深挖)。
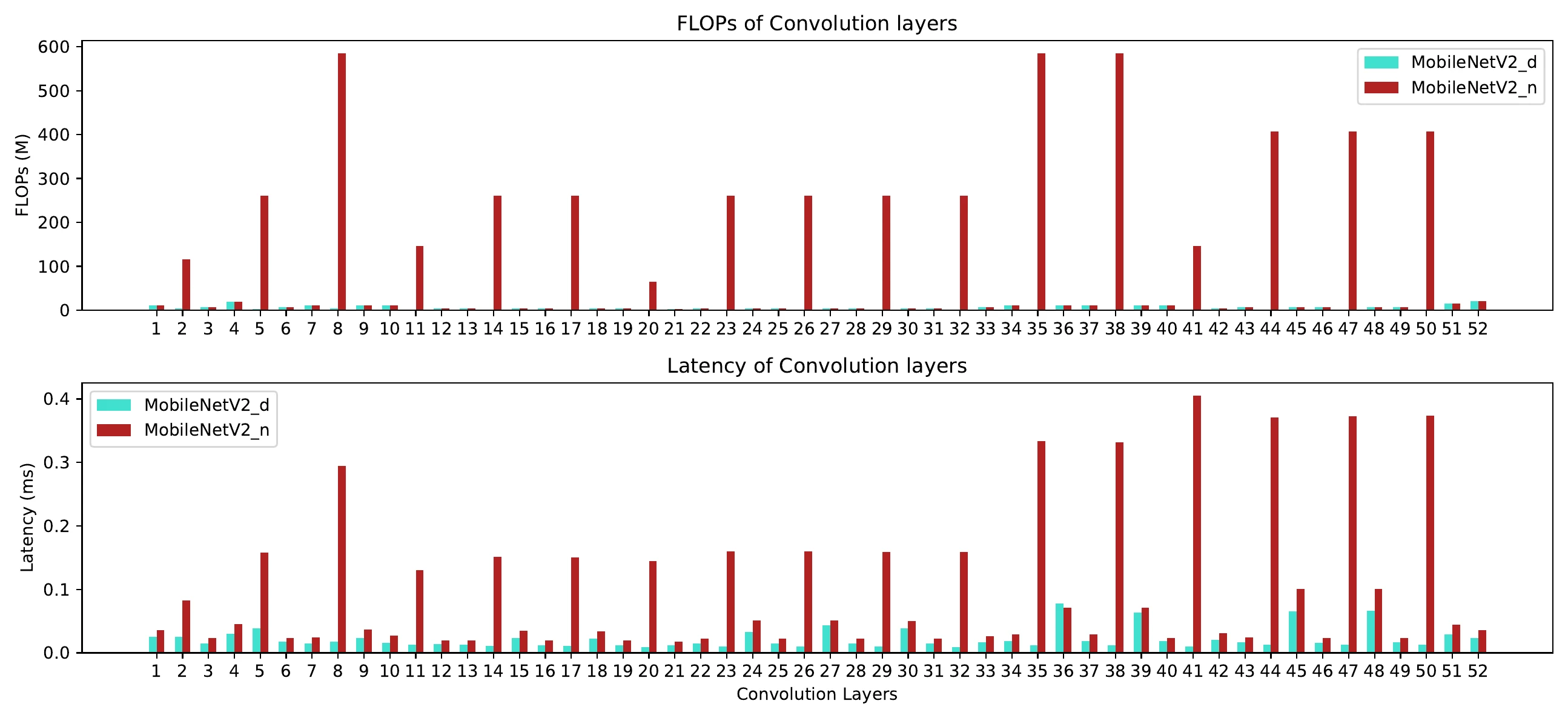
最后看深度分离卷积(depthwise convolution)。下图里 MobileNetV2_d 用深度分离卷积,MobileNetV2_n 把所有深度分离卷积换成普通卷积。MobileNetV2_d 相比 MobileNetV2_n,FLOPs 小了 18 倍,实际提速却不到 4 倍——逐层对比可以看到,深度分离卷积大幅砍掉了 FLOPs,却并不怎么减小访存开销:
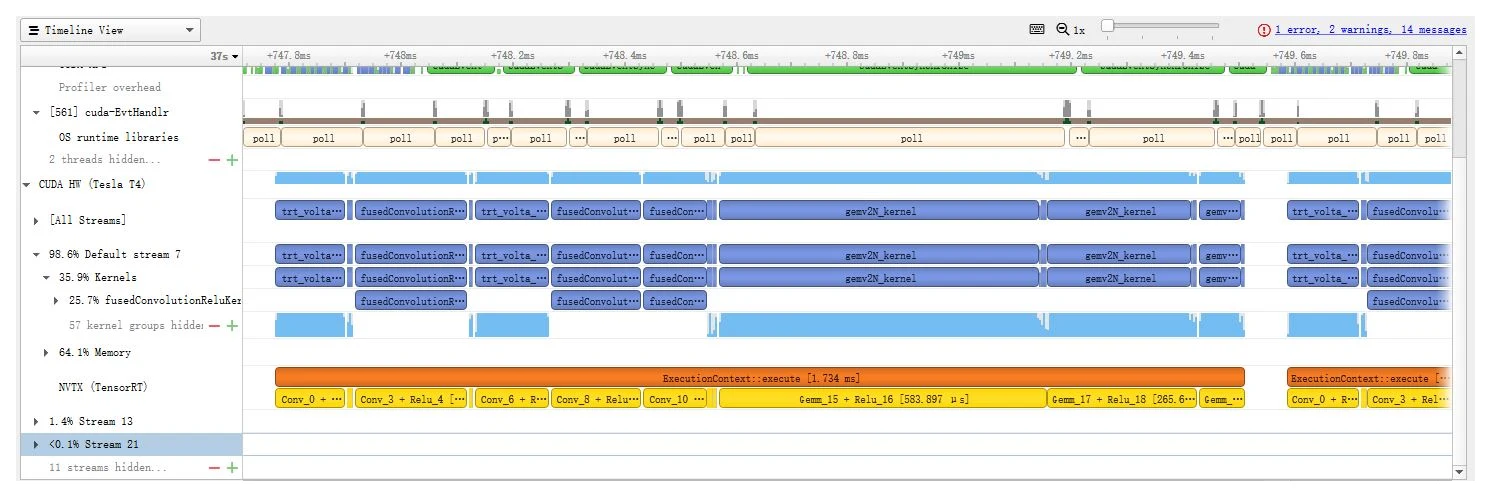
既然时间主要花在卷积层和全连接层上,在 GPU 平台上就可以用 NVIDIA Nsight Systems 或 TensorRT 自带的 Profiler 做性能分析(profiling),直接测出各部分的时间开销,再有针对性地优化——因为优化不同部分对整体的提升是不一样的,这就是 Amdahl 加速定律:
其中 是被优化部分占原执行时间的比例, 是这部分本身的加速比。
空间:参数量与峰值内存
空间上的效率主要看运行时的内存开销(memory footprint)。它同样取决于网络结构和软件实现(比如有的推理框架会及时释放已被下一层用过的特征图,或对深度分离卷积用 inplace 实现,或用 FP16 推理)。这里假定所有参数都以 32 位浮点存储和计算,只围绕网络结构本身讨论。
内存开销有两个来源:一是网络自身的参数量(运行时占内存,存储时占磁盘);二是运行时的峰值内存,主要来自运行中的特征图,它不仅和网络结构有关,还取决于输入大小(batch、长宽、通道数)。学界讨论参数量的多,讨论峰值内存的少,但对多分支结构来说,在分支较多的节点做运算时要同时保存大量特征图,峰值内存可能很大,哪怕这类网络自身参数量并不多。
和 FLOPs 一样,内存开销也能在不依赖运行时平台的情况下较准确地算出来。先看参数量,同样主要来自卷积层和全连接层。卷积层(含 bias):
全连接层:
至于峰值内存,假定推理过程中只存网络权重和当前需要的特征图,那么运行时的最大内存开销,就约等于全部权重参数占用的内存,加上运行中最大的那一组特征图占用的内存。
把这两条线——任务精度与运行效率——的指标都定义清楚,后面所有的结构设计、训练技巧、剪枝、量化,才有一个能对齐的标尺。
参考资料
- He, Kaiming, et al. Deep Residual Learning for Image Recognition. CVPR, 2016.
- Howard, Andrew G., et al. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv:1704.04861, 2017.
- Sandler, Mark, et al. MobileNetV2: Inverted Residuals and Linear Bottlenecks. CVPR, 2018.
- Howard, Andrew, et al. Searching for MobileNetV3. arXiv:1905.02244, 2019.
- Paszke, Adam, et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. NeurIPS, 2019.
- Abadi, Martín, et al. TensorFlow: A System for Large-Scale Machine Learning. OSDI, 2016.