知识蒸馏:让小网络模仿大网络
知识蒸馏(knowledge distillation)是一种常见的提升神经网络训练精度、加速收敛的方法,经常用于模型压缩之后的微调(finetune)以及 NAS 中的小网络训练。
它的思路很直接:把某个高精度教师网络(teacher model)的输出当作某个学生网络(student model)的标签,让学生模仿教师的行为。
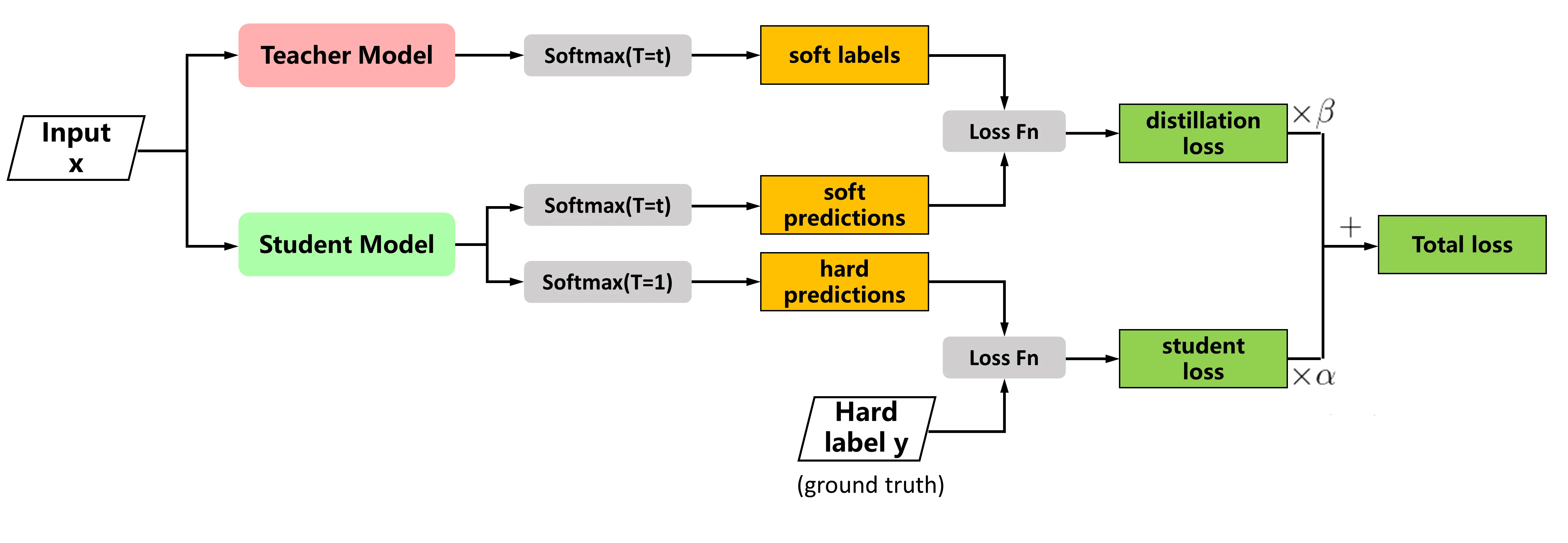
经典蒸馏:软标签与温度
最常见的实现,是把学生网络自身的分类损失,加上教师与学生输出之间的蒸馏损失,作为新的损失。记 为交叉熵, 为 softmax 的温度, 为学生输出、 为教师输出, 为标签, 为两项损失的权重:
第一项是学生对真实标签的普通分类损失,第二项是让学生的软输出去逼近教师的软输出。其中带温度的 softmax 为:
时就是常见的 softmax; 会让类别上的概率分布更平滑,学生模仿起来更容易——这就是上图里的 soft label 与 soft prediction。
在中间层蒸馏:FitNets 与 FSP
除了在最后的输出层迁移知识,FitNets 提出用 hints training,在教师与学生网络的某个中间层之间迁移知识,给学生提供”提示(hints)“。
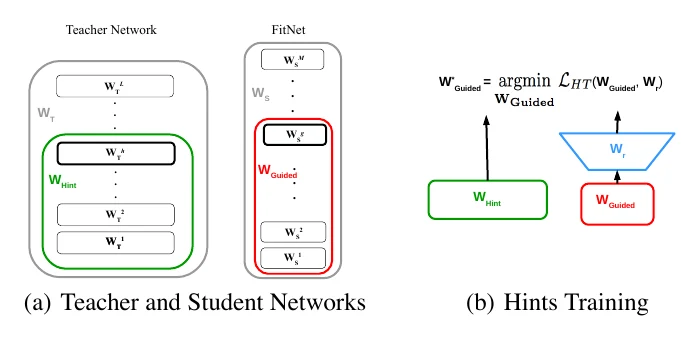
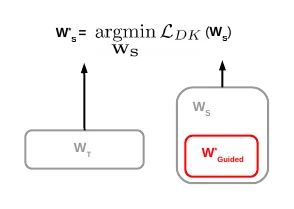
其中的 hint loss 如下, 是用于匹配维度的额外层、 是它的参数,、 分别是教师和学生的中间层输出:
做完 hints training 之后,还要再通过输出层的蒸馏把整个学生网络训练好。
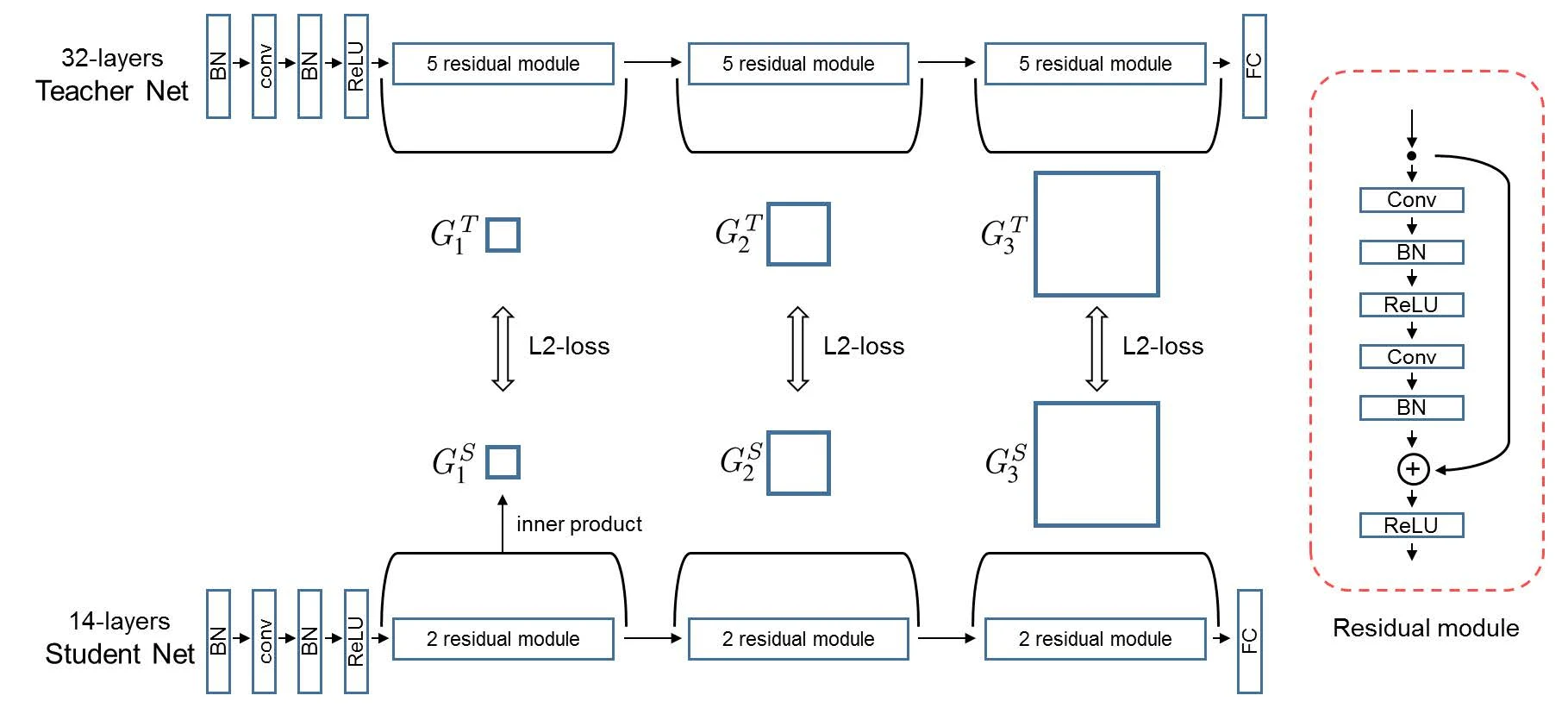
另一项工作(A Gift from Knowledge Distillation)提出用 FSP 矩阵迁移知识——FSP 矩阵的每个元素由两层特征图之间的内积得到。
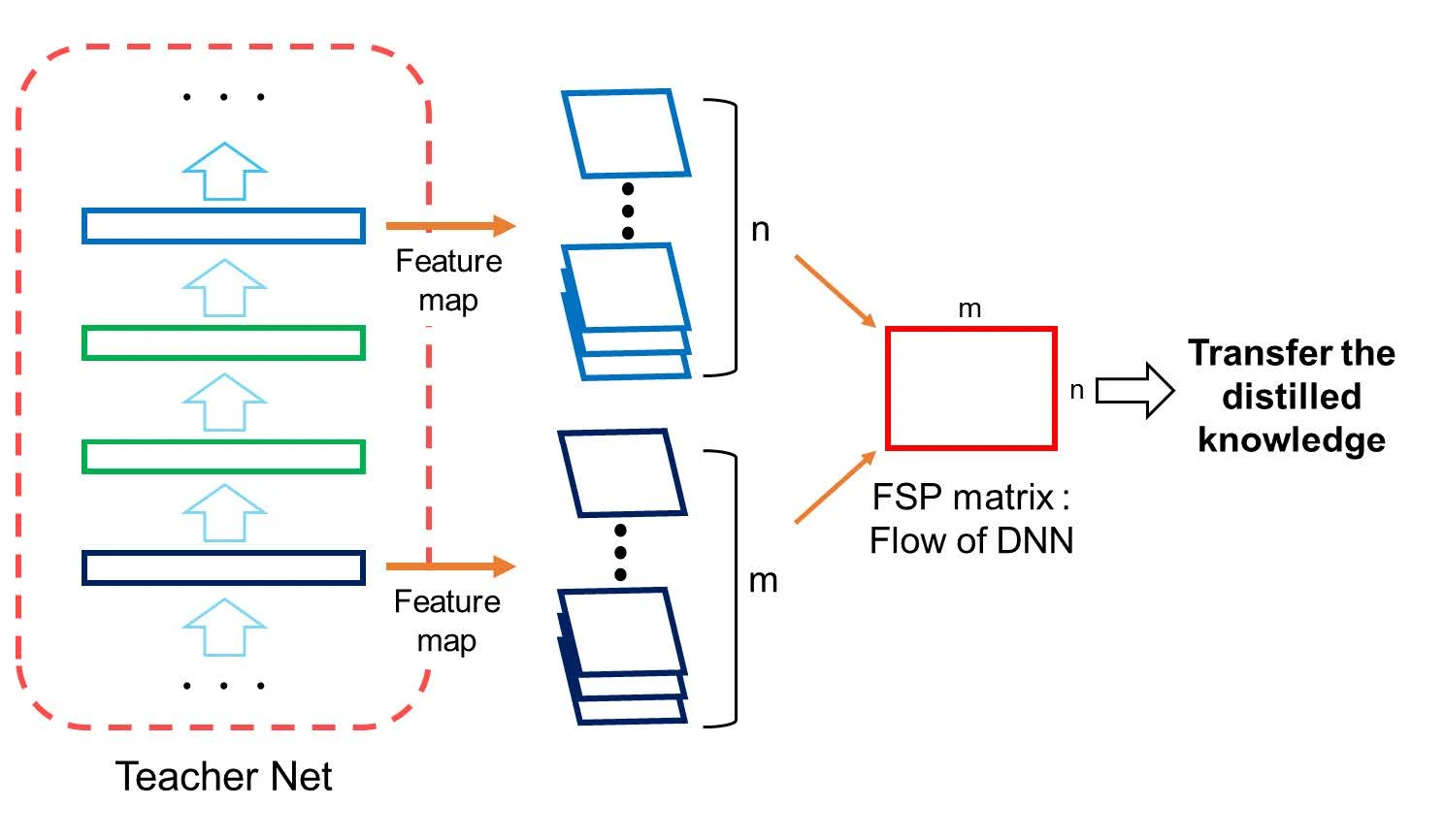
和 FitNets 类似,它也在中间层迁移,但是在多个层上进行(而不是只在某一个中间层)。这种方法适用于教师与学生结构相似、但深度不同的场景,从而保证 FSP 矩阵维度一致、可以计算 L2 损失。
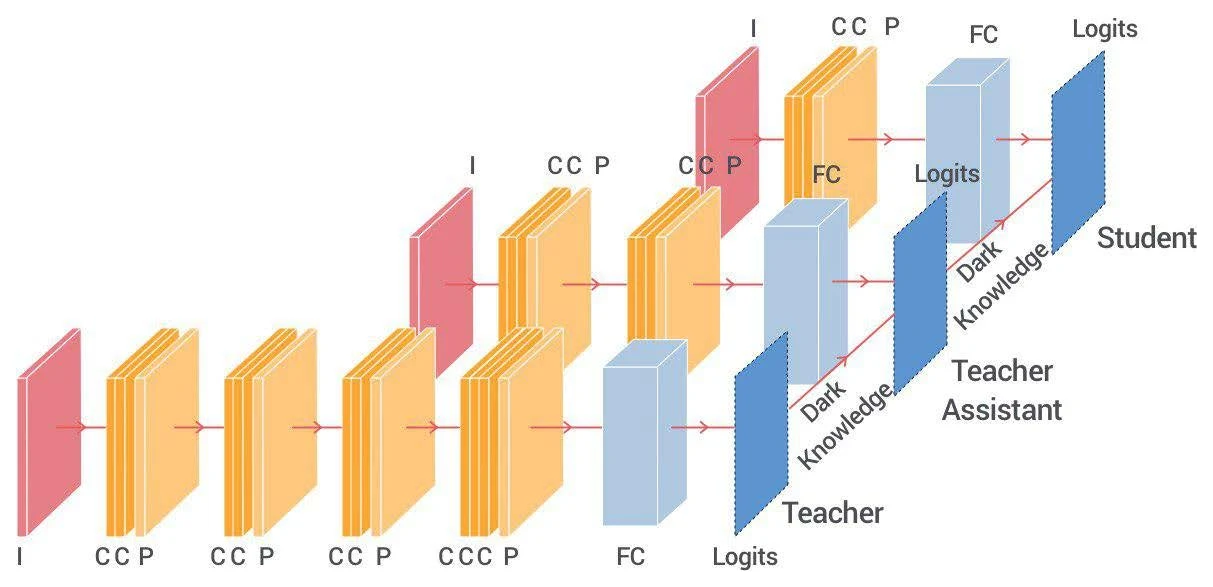
助教网络:让差距别太大
考虑到教师与学生之间可能差距过大、知识不好迁移,TAKD 在两者之间加了一个助教网络(teacher assistant):知识先从教师传到助教,再从助教传到学生,中间多一层过渡,让迁移更平滑。
互相学习:DML
前面几种都是学生单向地从教师学。DML(Deep Mutual Learning) 则让一组网络互相学习:两个有差异的网络结构在训练中彼此互补,各自都达到更好的效果。训练时,每个网络的损失不仅含输出与标签的交叉熵,还含与另一个网络输出之间的 KL 散度。

两个网络的损失 、 定义为:
其中 是交叉熵损失, 是 KL 散度(Kullback-Leibler divergence):
参考资料
- Hinton, Geoffrey, Vinyals, Oriol, Dean, Jeff. Distilling the Knowledge in a Neural Network. arXiv:1503.02531, 2015.
- Gou, Jianping, et al. Knowledge Distillation: A Survey. arXiv:2006.05525, 2020.
- Romero, Adriana, et al. FitNets: Hints for Thin Deep Nets. arXiv:1412.6550, 2014.
- Yim, Junho, et al. A Gift from Knowledge Distillation: Fast Optimization, Network Minimization and Transfer Learning. CVPR, 2017.
- Mirzadeh, Seyed Iman, et al. Improved Knowledge Distillation via Teacher Assistant. AAAI, 2020.
- Zhang, Ying, et al. Deep Mutual Learning. CVPR, 2018.