Tuning Deep Learning: From Manual Alchemy to Automated Search
Tuning is both a dark art and decisive in deep learning — training is often jokingly called “alchemy.” This post covers some manual tuning tricks first, then automated methods and tools.
Manual tuning
Take ImageNet classification: most hyperparameters to tune relate to optimization — batch size (BS below), the optimizer choice, and optimizer-related knobs like learning rate (LR below), the LR decay schedule, momentum, and weight decay.
Batch size and learning rate
BS trades off two ways. On hardware: too large risks out-of-memory (OOM), too small underuses the compute and slows training. On optimization: a larger BS estimates the full-dataset gradient better, so training is steadier and less prone to diverging — which is why a larger BS usually pairs with a larger LR to speed things up. A common rule is to scale BS and LR proportionally: e.g. BS=256 → LR=0.1, so with 4 GPUs at BS=256 each (total BS=1024) the LR should grow to 0.4. BS is also usually set to for parallel efficiency.
Optimizers
Optimizing a network is, at heart, estimating the weights to minimize an objective . With samples:
Standard gradient descent updates over all samples ( is the learning rate):
But is huge in deep learning, so we estimate the gradient from a mini-batch (size = BS, denoted ) — mini-batch SGD:
Below, denotes this mini-batch average gradient. In practice we often add momentum, carrying a fraction of the previous step into this one:
Nesterov momentum is similar but takes the momentum step first and computes the gradient there (PyTorch defaults to , i.e. no momentum; I usually set ):
SGD’s learning rate is constant. The following adapt it. Adagrad scales the LR by the accumulated sum of squared gradients, with no extra hyperparameter beyond :
RMSprop uses a decay factor to fade the history (PyTorch default ):
Adam adds gradient momentum on top of RMSprop, with two extra hyperparameters (PyTorch defaults ):
LR decay and weight decay
Every optimizer has at least the learning rate to tune. LR is probably the single most important hyperparameter; it interacts with BS, optimizer, data, and model, with no universal answer — the usual rule is to use as large an LR as you can without diverging. LR typically warms up (rises slowly) then decays, with step, exponential, or cosine schedules:
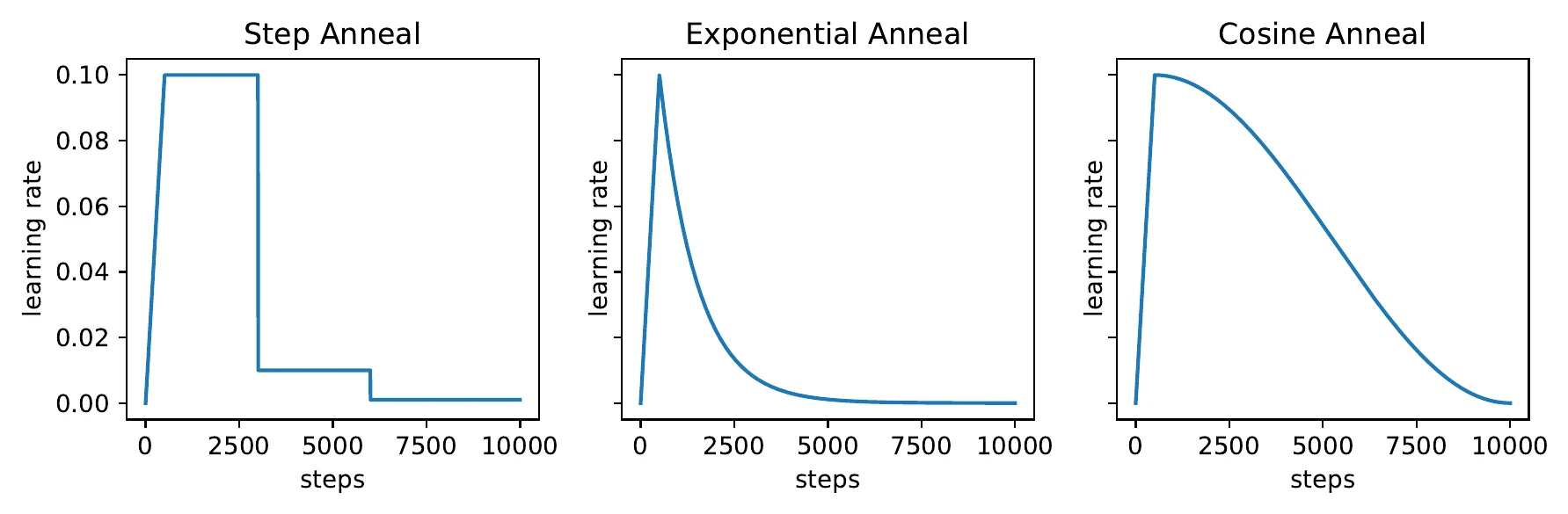
Beyond preset schedules, you can use automatic LR control: watch a training metric (e.g. training loss) and preset rules — decay the LR if the loss stalls for a while, decay it if the loss suddenly spikes, raise it a bit if the loss is decreasing too slowly. Such rule-based methods are useful in automated deep learning, but the rules themselves take time to design and must cover many tasks. I used this in my winning solution for the image track of the NeurIPS 2019 AutoDL competition.
Finally, weight decay: a penalty added to the objective (usually L1/L2; PyTorch defaults to L2) to fight overfitting. The coefficient is usually small — I often use . A handy tip: don’t apply weight decay to BN parameters — they’re more sensitive than conv/FC weights, and adding it actually lowers accuracy slightly.
Automatic hyperparameter optimization
Automatic HPO is part of AutoML (which also covers meta-learning, neural architecture search, etc.). Here we only discuss HPO via black-box optimization, which splits into two families: model-free methods and Bayesian optimization.
Model-free methods
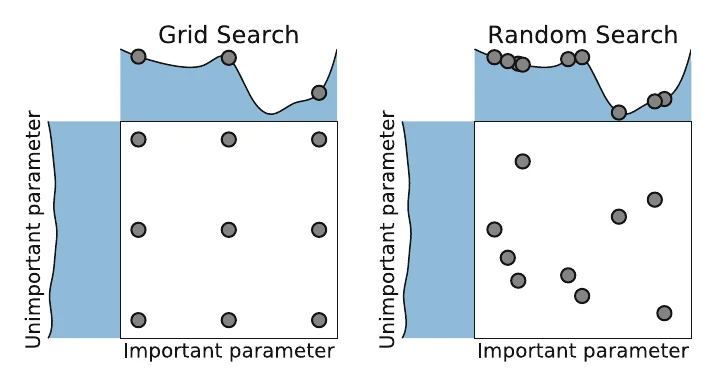
The simplest is grid search: give each hyperparameter a finite set of candidate values, take the Cartesian product, and validate each. The problem is the curse of dimensionality — compute explodes exponentially as hyperparameters grow.
The alternative is random search: sample randomly in the solution space until the budget runs out. When some hyperparameters matter and others don’t, random search is often more efficient than grid search; it also parallelizes better (no communication needed) and makes a solid baseline — given enough compute its result approaches the optimum, and it can seed other algorithms.
There are also population-based algorithms (genetic / evolutionary / particle swarm): maintain a population of hyperparameters and evolve a better next generation via local operations (selection, crossover, mutation) — simple, handles diverse data types, and parallelizes well. A strong one is CMA-ES (Covariance Matrix Adaptation Evolution Strategy): sample from a multivariate Gaussian whose mean and covariance are continually optimized as evolution proceeds; it scores well on the Black-Box Optimization Benchmarking (BBOB).
Bayesian optimization
Bayesian optimization’s biggest strength is finding good hyperparameter combinations in very few steps, ideal when the objective itself is expensive (like deep learning). It has two parts: a probabilistic surrogate model of the black-box objective, and an acquisition function that picks the next point to observe — the latter balancing exploration and exploitation. The process iterates: each round fit the surrogate to all observations so far, then use the acquisition function to choose the next point.
The most common surrogate is the Gaussian process (GP): expressive, smooth, and closed-form. For a new point , the GP’s prediction is Gaussian with mean and variance (where is the covariance vector between the new point and prior points, the covariance matrix among prior points, the prior observed values):
A common acquisition function is Expected Improvement (EI), which seeks the point of greatest expected improvement to observe next:
where is the current best observation and are the standard normal’s CDF and PDF. Since each round must find the acquisition function’s maximum, computing it has to be far cheaper than the objective — exactly the case when the objective is a heavy deep-learning task.
Standard GP has limits: high complexity (fitting , predicting ), which struggles as observations grow; and standard kernels are inflexible in high dimensions. Hence extended kernels (random embeddings, cylindric kernels, additive kernels) and replacing the GP with a neural network or random forest — with many observations a neural network is usually faster and more parallelizable, while a random forest handles discrete hyperparameters better at lower complexity (fitting , predicting ).
Tools
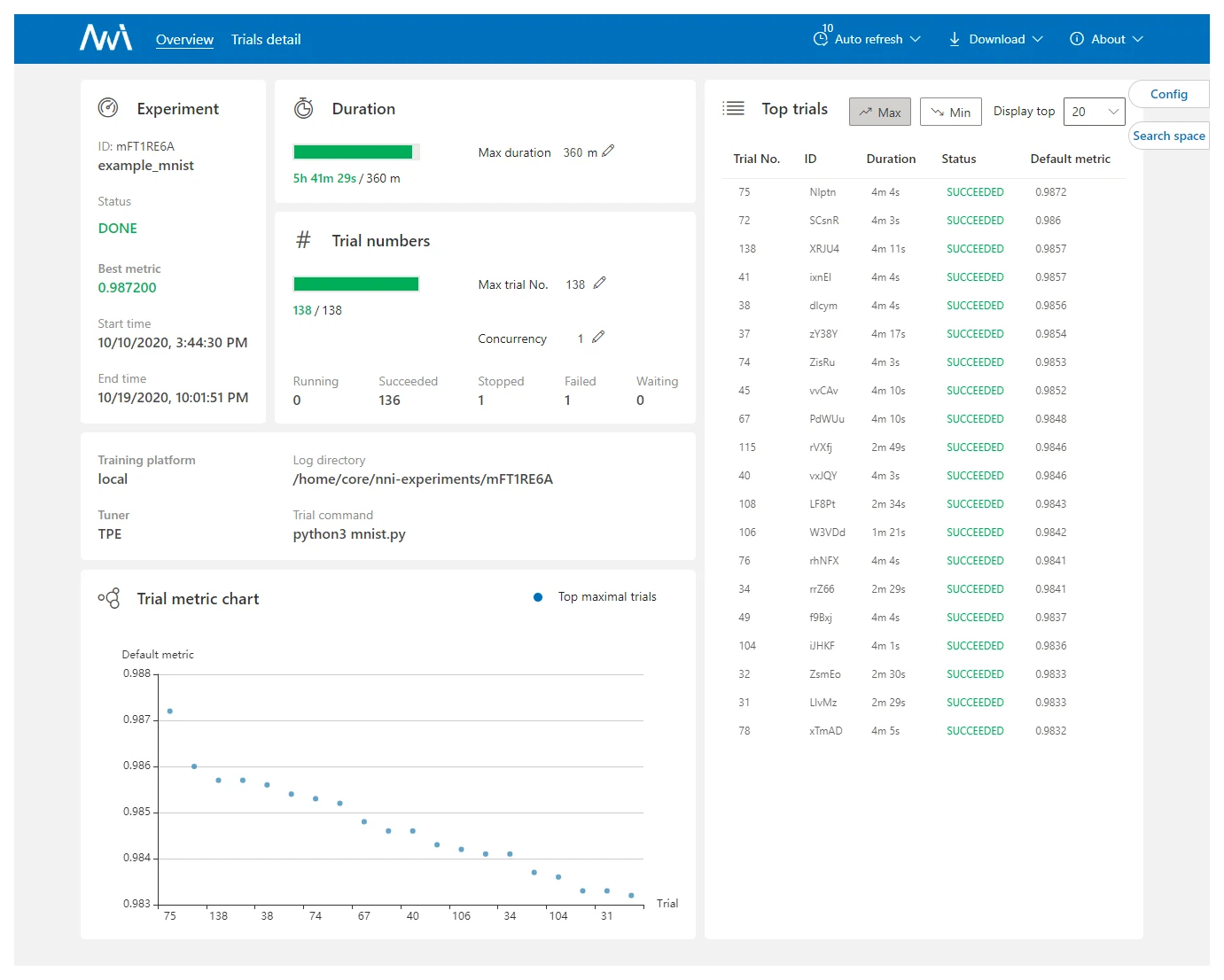
Many tools already package these algorithms with nice UIs and cross-platform support, e.g. RAY, NNI, and Auto-sklearn. NNI (Neural Network Intelligence) is a lightweight but powerful toolkit that automates feature engineering, architecture search, hyperparameter tuning, and model compression, supporting many training environments (local, remote servers, Kubeflow, AML, …), with a UI to monitor the optimization’s time cost and results at a glance:
References
- Deng, Jia, et al. ImageNet: A Large-Scale Hierarchical Image Database. CVPR, 2009.
- He, Tong, et al. Bag of Tricks for Image Classification with Convolutional Neural Networks. CVPR, 2019.
- Duchi, John, et al. Adaptive Subgradient Methods for Online Learning and Stochastic Optimization (Adagrad). JMLR, 2011.
- Kingma, Diederik P., Ba, Jimmy. Adam: A Method for Stochastic Optimization. arXiv:1412.6980, 2014.
- Sutskever, Ilya, et al. On the Importance of Initialization and Momentum in Deep Learning. ICML, 2013.
- Bergstra, James, Bengio, Yoshua. Random Search for Hyper-Parameter Optimization. JMLR, 2012.
- Hansen, Nikolaus. The CMA Evolution Strategy: A Comparing Review. 2006.
- Rasmussen, Carl Edward. Gaussian Processes in Machine Learning. 2003.
- Jones, Donald R., et al. Efficient Global Optimization of Expensive Black-Box Functions. Journal of Global Optimization, 1998.
- Li, Lisha, et al. Hyperband: A Novel Bandit-Based Approach to Hyperparameter Optimization. JMLR, 2017.
- Falkner, Stefan, et al. BOHB: Robust and Efficient Hyperparameter Optimization at Scale. arXiv:1807.01774, 2018.
- Zhang, Quanlu, et al. Retiarii: A Deep Learning Exploratory-Training Framework (NNI). OSDI, 2020.