Image Data Augmentation: From Random Crops to AutoAugment
Data augmentation is a go-to technique for fighting overfitting during training in computer vision. This post covers a few common image augmentations first, then some automated ones.
Common image augmentations
Random resized crop randomly crops the input and scales it to a target size. In PyTorch it’s torchvision.transforms.RandomResizedCrop(size, scale, ratio): size is the final size; scale is a range for the cropped area as a fraction of the original; ratio is a range for the crop’s aspect ratio.
Cutout masks out a random square region of the image (sets pixels to 0):

Random erase is like Cutout — also masking a random region — except it uses a rectangle rather than a square:

Mixup creates “virtual” training samples by randomly blending two inputs and their labels:
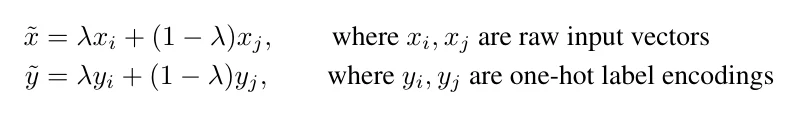
There are plenty of others too: random flips, random rotations, adjusting contrast, brightness, sharpness, and so on.
Automated augmentation
AutoAugment organizes many augmentation operations and their magnitudes into a search space, then automatically searches for the best-performing combination (each policy has two operations, each with a “probability” and a “magnitude” parameter).
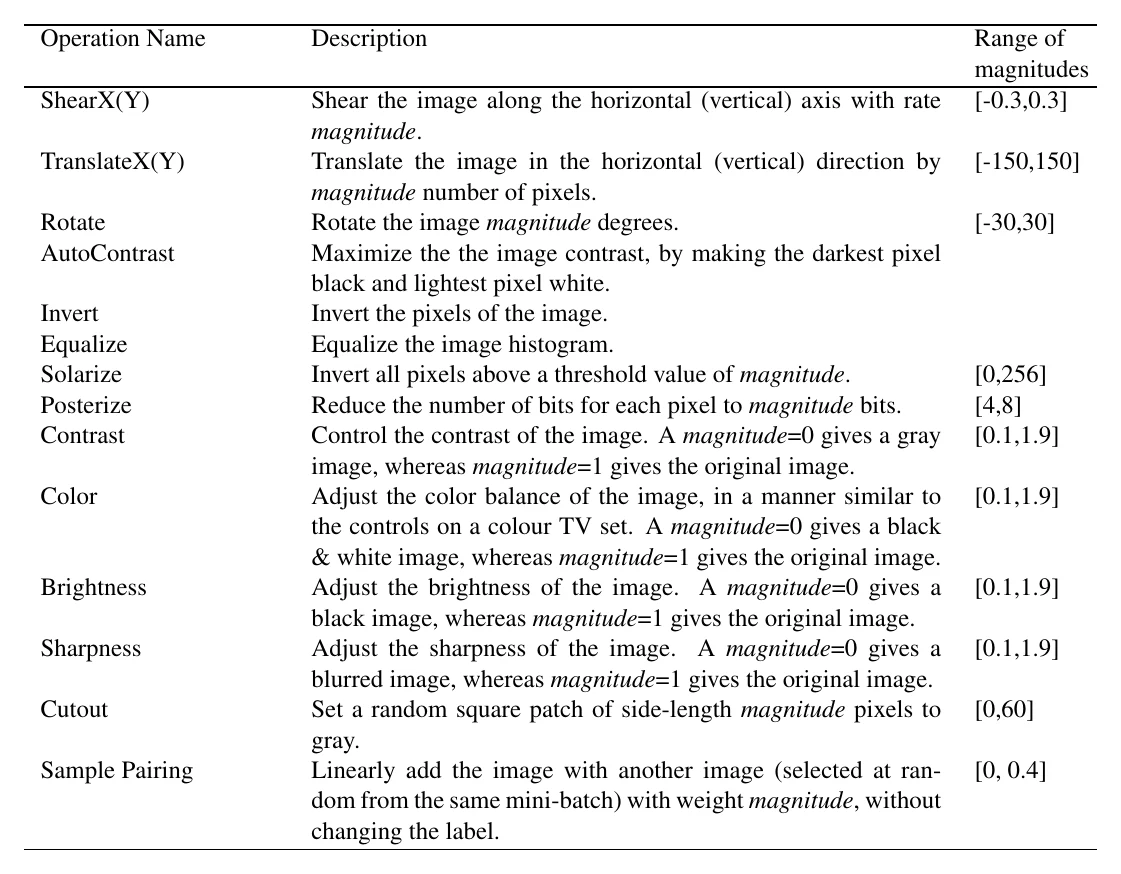
Its search resembles NAS — an RNN samples policies and reinforcement learning updates them. Each candidate policy requires training a network to validate it, which is very expensive.
Applying this combinatorial augmentation to ImageNet:

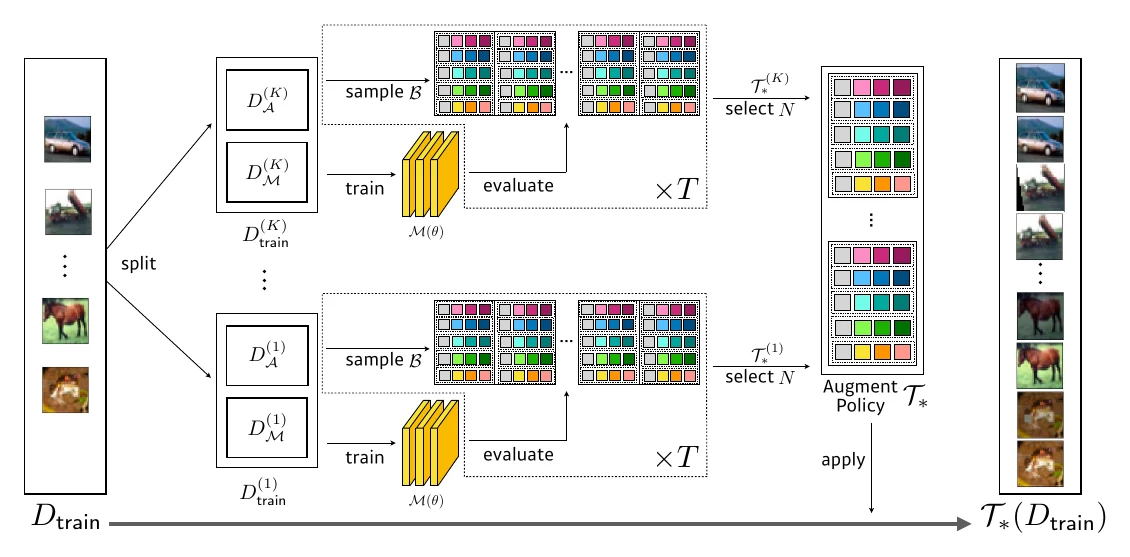
Fast AutoAugment is much faster and won the AutoCV competition; I also used it to win the image track of the AutoDL competition. Its speedup comes mainly from splitting the dataset into parts, searching the best augmentation policy on each, then merging them. In the competition I also swapped the paper’s Bayesian optimization for random search, using AutoAugment’s results as the search space.
One last note: beyond training-time augmentation, there’s Test Time Augmentation (TTA) — augment a test sample, run inference on each variant, then ensemble the results into the final output.
References
- DeVries, Terrance, Taylor, Graham W. Improved Regularization of Convolutional Neural Networks with Cutout. arXiv:1708.04552, 2017.
- Zhong, Zhun, et al. Random Erasing Data Augmentation. AAAI, 2020.
- Zhang, Hongyi, et al. mixup: Beyond Empirical Risk Minimization. arXiv:1710.09412, 2017.
- Shorten, Connor, Khoshgoftaar, Taghi M. A Survey on Image Data Augmentation for Deep Learning. Journal of Big Data, 2019.
- Cubuk, Ekin D., et al. AutoAugment: Learning Augmentation Policies from Data. arXiv:1805.09501, 2018.
- Lim, Sungbin, et al. Fast AutoAugment. NeurIPS, 2019.
- Zoph, Barret, Le, Quoc V. Neural Architecture Search with Reinforcement Learning. arXiv:1611.01578, 2016.