The Evolution of CNN Architectures: From LeNet to SENet
To design efficient networks, it helps to know how the field made networks deeper and stronger over the years. This post follows the ILSVRC (ImageNet Large Scale Visual Recognition Challenge) timeline through the milestone CNN architectures. (Accuracy numbers below are all from torchvision.)
LeNet-5: where CNNs began
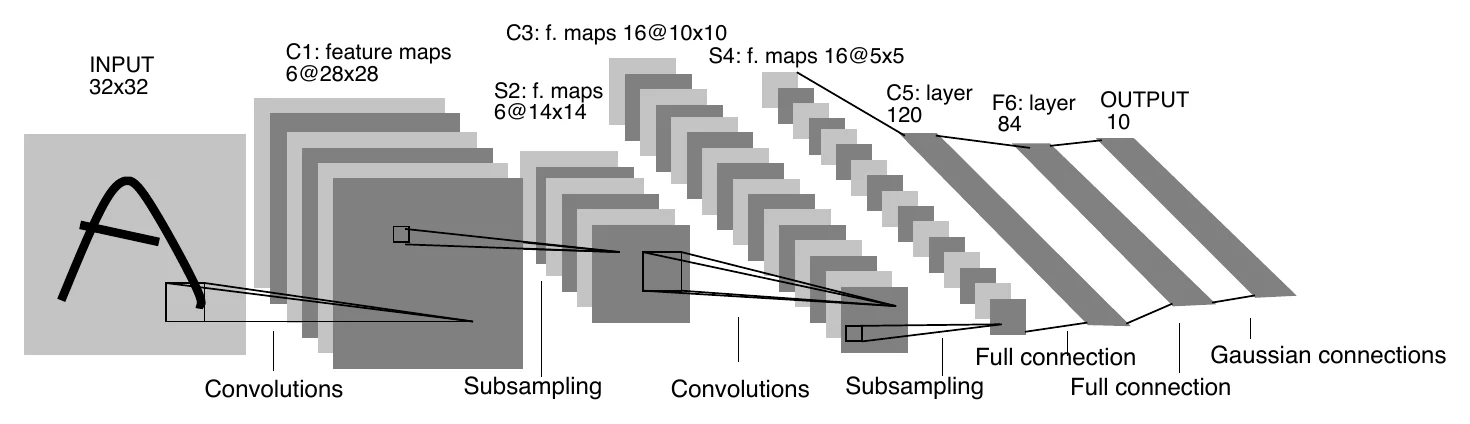
Convolutional networks trace back to LeCun’s 1998 paper, which proposed LeNet-5 for handwritten character recognition — on the dataset we all know as MNIST: 50,000 handwritten 0–9 characters, each and single grayscale channel.

Apart from its fully-connected layers, LeNet-5 has just 5 layers (3 conv + 2 pooling) — the earliest CNN used for image recognition.
AlexNet: lighting the fuse
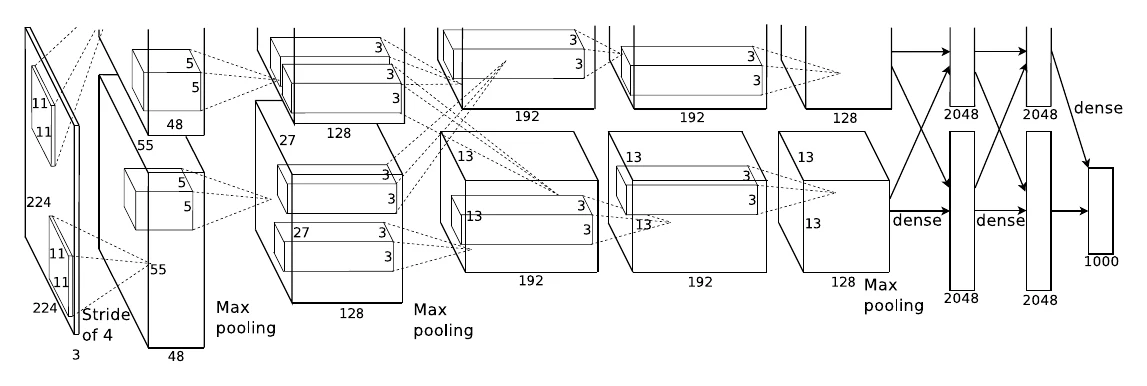
CNNs really took off thanks to ILSVRC — the large-scale recognition challenge on ImageNet (the ILSVRC2012 set has 1000 classes, 1.28M training and 50K test images, over 100GB total). AlexNet won it in 2012. Training a deep CNN at ImageNet scale leaned on the rise of GPUs: CNNs are highly parallelizable, and that paired with GPU compute let deep CNNs shine on large-scale recognition. AlexNet has 5 conv layers and 3 max-pooling layers — not many more than LeNet-5 — but every layer computes at higher resolution, so the compute is far larger. It reached 56.55% Top-1 and 79.09% Top-5.
GoogLeNet / Inception: a multi-branch module
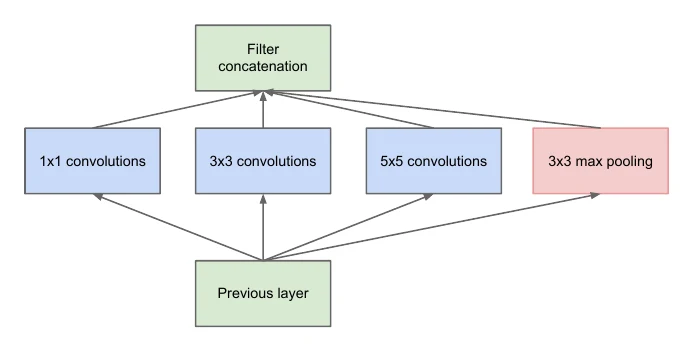
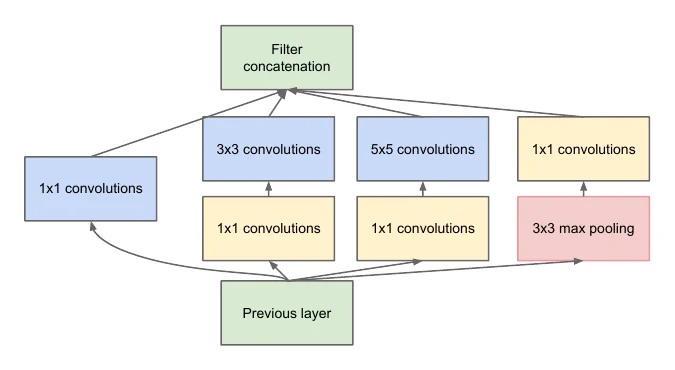
In 2014 Google’s GoogLeNet (a.k.a. Inception V1, later V2/V3/V4) won ILSVRC2014. It introduced the Inception module: process the input with several different conv layers in parallel, then concatenate. GoogLeNet hit 69.78% Top-1 and 89.53% Top-5 on ILSVRC2012.
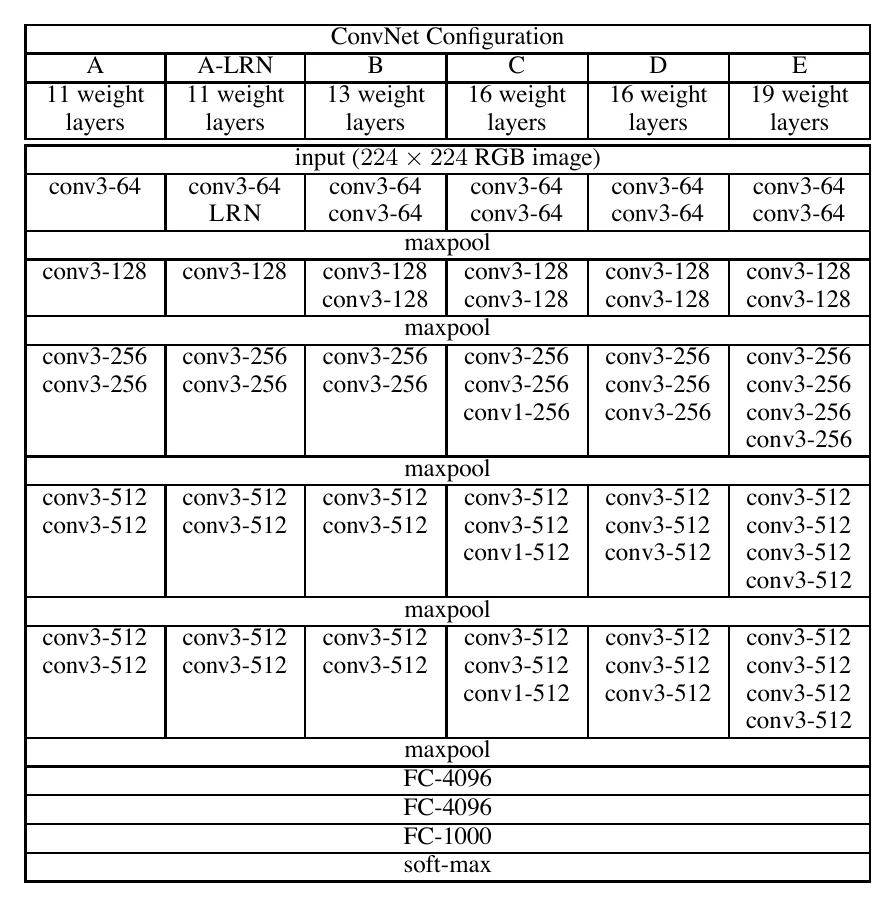
VGGNet: going “very deep”
Born around the same time as GoogLeNet, VGGNet upgraded “deep convolution” to very deep convolution right in its title. Its versions differ only in the number of conv layers and whether Batch Normalization is used. VGG19 + BN reached up to 74.24% Top-1 and 91.85% Top-5.
Batch Normalization and the normalization family
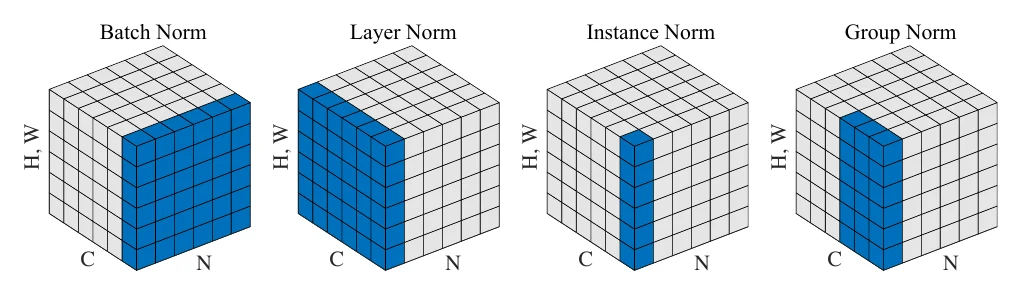
Some VGG versions use a Batch Normalization (BN) layer. BN normalizes the input 4D tensor and applies an affine transform, effectively curbing covariate shift — so you can use a larger learning rate, train faster, and train more stably without diverging.

BN is now indispensable in deep learning. Close relatives include Layer Normalization, Instance Normalization, and Group Normalization, differing mainly in the dimensions and scope they normalize over:
ResNet: residual connections, hundreds of layers
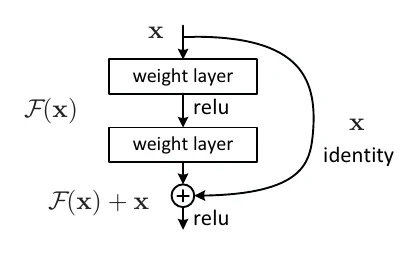
The 2015 ResNet is one of the most exciting results in recent years, sweeping ILSVRC2015 and COCO2015 across classification, detection, and segmentation. Its residual learning made even very deep networks easy to train — the paper went to hundreds of layers, even trying thousands, and showed that such depth has no trouble fitting the training data (though it overfits). ResNet-152 reached 78.32% Top-1 and 94.06% Top-5 on ILSVRC2012.
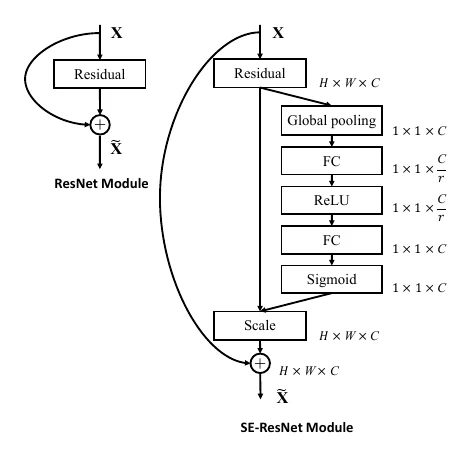
SENet: attention over channels
The 2016 SENet (Squeeze-and-Excitation Network) won the last-ever ILSVRC (2017). It introduced the Squeeze-and-Excitation module, which fuses information across a feature map’s channels — a form of attention.
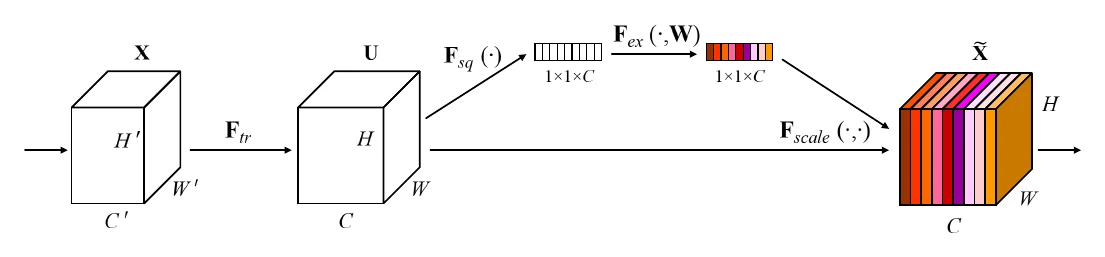
The SE module drops easily into other architectures. Embedded in ResNet’s residual block, an SE-ResNet of the same depth consistently beats plain ResNet by over 1% Top-1 on ILSVRC2012.
This chain of milestones — AlexNet bringing deep nets into view, VGG making them deep, Inception adding multi-branch modules and BN, ResNet adding residuals, SENet adding attention — is the foundation for all later design. But most were built to chase accuracy; to deploy on mobile with lower latency and memory, you need architectures designed to be compact.
References
- LeCun, Yann, et al. Gradient-Based Learning Applied to Document Recognition. Proceedings of the IEEE, 1998.
- Krizhevsky, Alex, Sutskever, Ilya, Hinton, Geoffrey E. ImageNet Classification with Deep Convolutional Neural Networks (AlexNet). NeurIPS / CACM, 2012/2017.
- Szegedy, Christian, et al. Going Deeper with Convolutions (GoogLeNet). CVPR, 2015.
- Simonyan, Karen, Zisserman, Andrew. Very Deep Convolutional Networks for Large-Scale Image Recognition (VGG). arXiv:1409.1556, 2014.
- Ioffe, Sergey, Szegedy, Christian. Batch Normalization. arXiv:1502.03167, 2015.
- Ba, Jimmy Lei, et al. Layer Normalization. arXiv:1607.06450, 2016.
- Ulyanov, Dmitry, et al. Instance Normalization: The Missing Ingredient for Fast Stylization. arXiv:1607.08022, 2016.
- Wu, Yuxin, He, Kaiming. Group Normalization. ECCV, 2018.
- He, Kaiming, et al. Deep Residual Learning for Image Recognition (ResNet). CVPR, 2016.
- Hu, Jie, Shen, Li, Sun, Gang. Squeeze-and-Excitation Networks (SENet). CVPR, 2018.
- Deng, Jia, et al. ImageNet: A Large-Scale Hierarchical Image Database. CVPR, 2009.