ShuffleNetV2
Abstract
Many network designs today only consider indirect metrics (such as FLOPs) for computational complexity, but direct metrics (like speed) are not solely determined by FLOPs. Factors like MAC (memory access cost) and platform characteristics also impact speed. This paper aims to focus on direct metrics on specific platforms, which is better than just considering FLOPs. Based on a series of controlled experiments, some guidelines for efficient networks are proposed. Following these guidelines, a new network structure called ShuffleNetV2 is introduced. Comprehensive ablation experiments show that this model achieves state-of-the-art performance in terms of the trade-off between performance and accuracy.
1. Introduction
Since AlexNet achieved great success on ImageNet, classification accuracy on ImageNet has been further improved by new neural networks like VGG, GoogLeNet, ResNet, DenseNet, ResNeXt, SE-Net, and even automated network architecture search. Besides accuracy, computational complexity is another factor to consider. Real-world applications are often constrained by various platforms, which has led to the design of many lightweight neural network structures and better speed-accuracy trade-offs, such as Xception, MobileNet, MobileNetV2, ShuffleNet, and CondenseNet. In these works, group conv and depth-wise conv are crucial.
To evaluate computational complexity, FLOPs (defined in this paper as the number of mult-adds) is commonly used. However, FLOPs is only an approximate indirect metric and not the direct metric we care about, such as speed and latency. This contradiction has been noticed in recent work. For example, MobileNetV2 and NASNET-A have similar FLOPs, but MobileNetV2 is much faster. The diagram below shows models with similar FLOPs but possibly different speeds . Therefore, using only FLOPs as a metric is insufficient and may lead to suboptimal designs.
. Therefore, using only FLOPs as a metric is insufficient and may lead to suboptimal designs.
The contradiction between indirect metrics (FLOPs) and direct metrics (speed) mainly arises from two aspects (metrics and platform): First, many key factors affecting speed are not considered, such as MAC (memory access cost, with group conv being an important component, which may become a bottleneck for powerful computing units like GPUs), and DOP (degree of parallelism, where models with high DOP may be much faster than those with low DOP under the same FLOPs). The second reason is platform dependency. For example, operations like tensor decomposition can reduce FLOPs by 75%, but the running speed on CPU after decomposition is even slower than on GPU. This was later found to be due to special optimization for 3x3 convolutions in the latest CUDNN library, so it’s not simply that 3x3 conv is 9 times slower than 1x1 conv.
Based on these observations, two principles should be followed in efficient neural network design: use direct metrics instead of indirect metrics, and measure on specific platforms. Based on these two principles, more effective neural network structures are proposed. In the second chapter, we first analyze the runtime performance of two representative state-of-the-art neural networks (ShuffleNetV1, MobileNetV2), and then propose four guidelines for efficient network design, going beyond just considering FLOPs. However, these guidelines are platform-independent, and we conducted different controlled experiments to verify them on two platforms (GPU and ARM) with code optimization to ensure our conclusions are state-of-the-art.
In the third chapter, ShuffleNetV2 is designed, and through comprehensive validation experiments in the fourth chapter, it is proven to be more accurate and faster than previous networks on both platforms.
2. Practical Guidelines for Efficient Network Design
This study is conducted on two widely used hardware platforms with industrial-grade optimized CNN libraries. Note that our CNN library is more efficient than most open-source libraries, so our observations and conclusions are robust and have practical industrial value. GPU (single GTX1080TI, convolution library is CUDNN7.0, and CUDNN’s benchmarking function is activated to select the fastest algorithm for different convolutions), ARM (Qualcomm Snapdragon 810, implemented based on Neon, verified using a single thread), and other settings: full optimization enabled (such as tensor fusion), input image size: 224x224, all networks are randomly initialized, and the average runtime is evaluated 100 times.
For the initial study, we selected MobileNetV2 and ShuffleNetV1. Although there are only two, they represent recent trends. The core of these two networks is group conv and depth-wise conv, which are also the core of other state-of-the-art networks. The entire runtime decomposition diagram is as follows: . FLOPs only account for the convolution part, although it takes up most of the time, other components like data I/O, data shuffle, and element-wise operations also take up a significant portion, making FLOPs an inaccurate estimate of time. Based on the above observations, we analyzed runtime from several aspects and derived some practical experiences for efficient neural network design.
. FLOPs only account for the convolution part, although it takes up most of the time, other components like data I/O, data shuffle, and element-wise operations also take up a significant portion, making FLOPs an inaccurate estimate of time. Based on the above observations, we analyzed runtime from several aspects and derived some practical experiences for efficient neural network design.
G1. Equal channel width minimizes memory access cost
Many modern networks adopt depth-wise conv, where 1x1 convolution accounts for most of the complexity, with FLOPs as . Assuming enough memory to store input and output features and convolution kernel weights, MAC is , which is input features + output features + convolution kernel weights. By the arithmetic-geometric mean inequality, , and equality holds when , i.e., when the number of output channels equals the number of input channels, MAC is minimized. This is theoretical, and by stacking 10 blocks for evaluation, adjusting the number of channels to keep the overall FLOPs constant, the actual experimental results are as follows: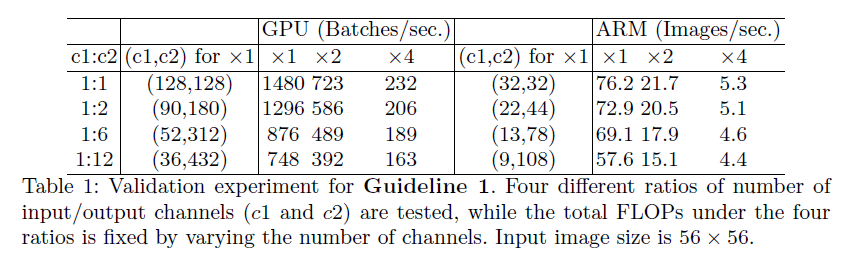
G2. Excessive group convolution increases MAC
Group conv is the core of many modern networks, allowing sparse connections between channels to reduce FLOPs. On one hand, more channels can be used under fixed FLOPs to increase network capacity (thus improving accuracy), but on the other hand, increasing channels also increases MAC. From the formula in the previous guideline, the relationship between FLOPs and MAC for 1x1 conv is: , where g is the number of groups. It can be seen that under fixed h, w, c1, c2, and B, increasing g increases MAC. By stacking 10 1x1 group convs to construct an evaluation network, results show that choosing a large group number is not always good, as the benefits of accuracy improvement may be offset by increased computational cost. Experimental results are as follows: .
.
G3. Network fragmentation reduces degree of parallelism
In the GoogLeNet series and auto-generated architectures, “multi-path” structures are widely used in each network block, where many small operations (fragmented operators) are applied instead of a few large operations. For example, in NASNET-A, fragmented ops (such as individual convolution/pooling operations in a block) is 13, while in some regular structures (like ResNet), it’s 2 or 3. Such fragmented structures have been shown to be beneficial for accuracy but may reduce efficiency because these operations are not friendly to highly parallel computing devices like GPUs. They also lead to additional overhead for kernel launch/synchronization. To quantify this impact, an experimental block was designed as follows: , with each block repeated 10 times. Results show that fragmentation significantly reduces speed on GPUs, while the speed reduction on ARM is less pronounced. Experimental results are shown:
, with each block repeated 10 times. Results show that fragmentation significantly reduces speed on GPUs, while the speed reduction on ARM is less pronounced. Experimental results are shown: .
.
G4. Element-wise operations are non-negligible
As shown in the previous images, element-wise operations (tensor addition, bias, ReLU, etc.) occupy a considerable amount of time, especially on GPUs. They have relatively small FLOPs but large MAC, especially depthwise conv as an element-wise operation, because it has a large MAC/FLOPs ratio. Experiments were conducted on bottleneck structures, targeting ReLU and shortcut: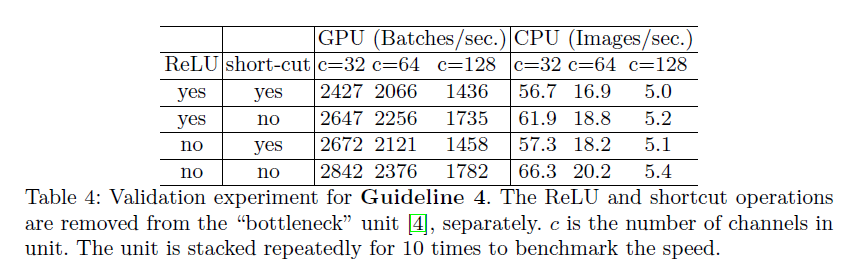
Conclusion and Discussion
Summary: 1) Use balanced convolutions (equal input and output channels) as much as possible, 2) Understand the cost of group-conv, 3) Reduce network fragmentation, 4) Reduce pointwise operations. Compared to theoretical aspects, more attention should be paid to platform characteristics and applied in actual network design. Many previous networks violated these rules, such as ShuffleNetV1 relying too much on group conv, violating G2, its bottleneck structure design violating G1, MobileNetV2’s bottleneck design violating G1, using ReLU on too thick feature maps violating G4, and auto-generated network structures being too fragmented, violating G3.
3. ShuffleNet V2: An Efficient Architecture
The main challenge of lightweight network design is the limited number of channels given a certain amount of computation. There are two ways to increase the number of channels under limited FLOPs: 1) pointwise group conv, 2) bottleneck structure. Channel shuffle structures were then introduced to increase communication between different channels. However, pointwise group conv and bottleneck structures both violate previous guidelines. The current problem is how to maintain a large number of evenly distributed channels without overly dense convolutions or too many groups.
Designs were made for the above needs: initially splitting channels, then not using groups in 1x1 conv, nor using bottleneck structures, but keeping input and output channels equal, and only performing ReLU and depthwise conv on one branch. Finally, concat and channel shuffle are performed. Concat, channel shuffle, and split are combined into one element-wise operation. Like V1, the network can be scaled using s by changing the number of channels. For simplicity, a half-split method is used during split. The structure of ShuffleNetV2 block is as follows: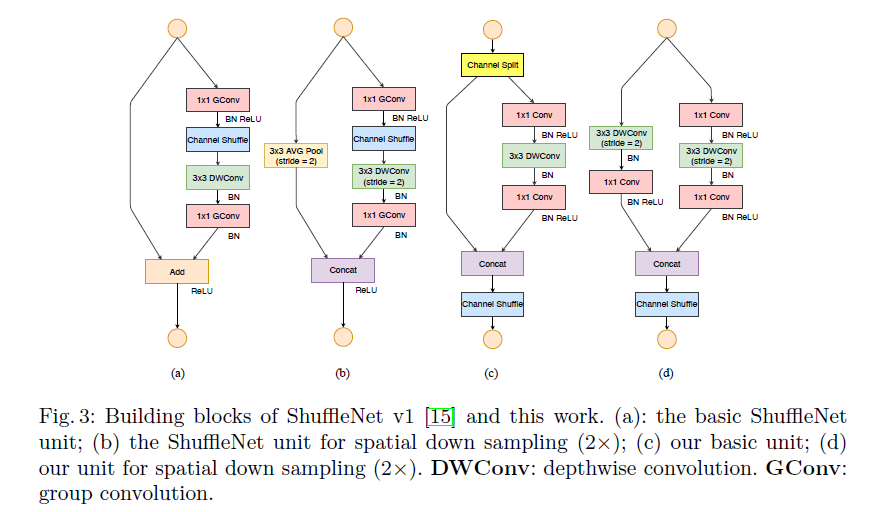
ShuffleNetV2 is very efficient, so it can have more channels and model capacity. Additionally, the half-split of features can be seen as a form of feature reuse, similar to DenseNet and CondenseNet. The comparison of feature reuse modes between DenseNet and ShuffleNetV2 is shown below: ShuffleNetV2 gains the same benefits in feature reuse as DenseNet but is more efficient, as subsequent experiments can demonstrate.
ShuffleNetV2 gains the same benefits in feature reuse as DenseNet but is more efficient, as subsequent experiments can demonstrate.
4. Experiment
The hyperparameters and protocols used in the experiments are exactly the same as ShuffleNetV1. Here are the experimental results, followed by a summary of the experiments: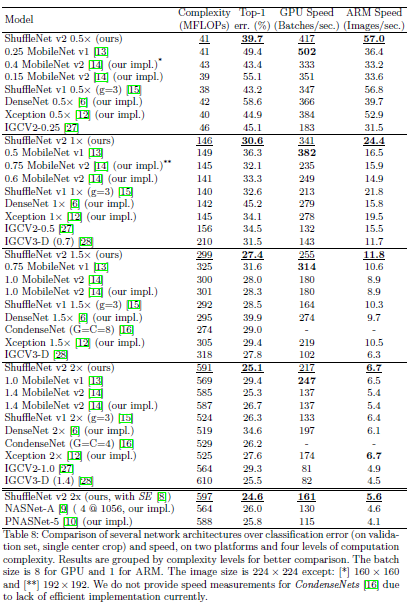
Accuracy vs. FLOPs: ShuffleNetV2 clearly outperforms all other networks, but at 40MFLOPs and 224x224 image size, it performs poorly due to too few channels. Compared to DenseNet, which also reuses features, this model is more efficient.
Inference Speed vs. FLOPs/Accuracy: MobileNetV2 is very slow with small FLOPs, possibly due to excessively high MAC. Although MobileNetV1 is less accurate, it is very fast on GPU, even surpassing ShuffleNetV2, possibly because it better meets previous design guidelines, especially G3, with MobileNetV1’s fragments being even smaller than ShuffleNetV2. Additionally, IGCV2 and IGCV3 are very slow, possibly due to excessive use of group conv, and these phenomena are consistent with our design guidelines. Current automatically searched neural network structures are relatively slow, likely due to having too many fragments, which violates G3, but this research direction is still promising. In terms of accuracy vs. speed, ShuffleNetV2 performs best on both GPU and CPU platforms.
Compatibility with other methods: When combined with other structures, such as SE (squeeze and excitation), ShuffleNetV2’s classification accuracy improves, indicating good compatibility.
Generalization to Large: ShuffleNetV2 also performs well as a large model, but when made very deep, residual connections are added to speed up convergence.
Object Detection: Its generalization performance was evaluated on the COCO dataset using the state-of-the-art lightweight detector Light-Head RCNN as the framework. It was trained on ImageNet and then fine-tuned for detection tasks. It was later found that Xception is better at detection tasks, possibly due to larger receptive fields in blocks. Inspired by this, a 3x3 depthwise conv was added before the first 1x1 conv, ultimately improving performance with a slight increase in FLOPs. Additionally, under detection tasks, the speed difference between different models is smaller than in classification tasks (excluding data copy overhead and detection-specific overhead). ShuffleNetV2* has the best accuracy and is faster than other methods, which raises another practical issue: how to increase receptive field size, which is crucial in high-resolution image object detection.
5. Conclusion
Network design should consider direct metrics rather than indirect metrics, providing effective guidelines for structural design and an efficient neural network, ShuffleNetV2. Comprehensive experiments fully demonstrate the model’s effectiveness, and it is hoped that this work will lead to more platform-related and practical network designs.