MobileNets: Efficient Convolutional Neural Networks for Mobile Vision
Abstract
For mobile and embedded vision applications, this paper proposes an efficient model called MobileNets, a lightweight neural network constructed using depthwise separable convolutions. The model uses two hyperparameters to balance accuracy and latency, and extensive experiments on ImageNet demonstrate its strong performance compared to other models. The experiments also showcase the power of ImageNet across various applications, including object detection, fine-grained classification, facial attributes, and large-scale geolocation.
1-Introduction
Since AlexNet popularized deep CNNs, CNNs have become ubiquitous in computer vision, with a general trend towards inventing deeper and more complex networks to achieve higher accuracy. However, these improvements have not enhanced network speed and size, which are critical for real-time applications in robotics, autonomous vehicles, AR, etc., on limited computing platforms.
This paper proposes an efficient network structure and a set of two hyperparameters to build models for these applications. Section 2 reviews previous work on building small models, Section 3 describes the MobileNet architecture and the two hyperparameters: width multiplier and resolution multiplier, Section 4 details experiments on ImageNet and various applications, and Section 5 concludes the paper.
2-Prior Work
Building efficient small-sized networks has become popular recently, with many methods classified into two types: compressing pre-trained networks or directly training small-sized networks. The proposed network structure allows builders to choose small-sized networks that meet resource constraints. MobileNet focuses on optimizing latency and producing small-sized networks, while many networks only consider size without speed.
MobileNets use depthwise separable convolutions, similar to the Inception model, to reduce computation in the early layers. Flattened networks use fully decomposed convolutions to build networks, showing the potential of decomposed networks. Factorized networks use similar convolution decomposition and topological connections. Other networks include Xception network: scaling depthwise separable filters, Squeezenet: using bottleneck, and other networks reducing computation: structured transform network, deep fried convnets.
Other methods for obtaining small-sized networks include shrinking, factorizing, and compressing pre-trained networks, with compressing involving product quantization, hashing, pruning, vector quantization, and Huffman coding. Factorization methods are discussed in [14,20]. Other methods include distillation (training small networks using large network outputs) and low bit networks.
3-MobileNet Architecture
This chapter first introduces the core depthwise separable filters, then the MobileNet network structure, and concludes with the introduction of two shrinking hyperparameters (width multiplier, resolution multiplier).
3.1-Depthwise Separable Convolutions
Depthwise separable convolution divides a standard convolution into two parts: depthwise convolution and 1x1 convolution. It also splits a convolution layer into two layers: filtering and combining. This decomposition significantly reduces computation and model size. A comparison between standard convolution and depthwise separable convolution is shown below: 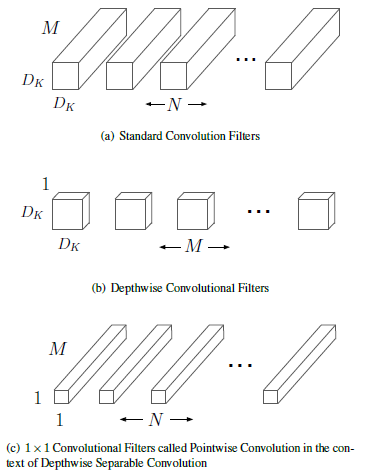
For a standard convolution, assuming input dimensions , output dimensions , and convolution kernel dimensions , under stride=1 and padding, the standard convolution computation formula is:
The computation cost of standard convolution is:
While the computation cost of depthwise separable convolution is:
The former is the computation cost of depthwise convolution, and the latter is the computation cost of 1x1 convolution. The reduction in computation between the two is:
Using a 3x3 convolution kernel reduces computation by 8-9 times with only a slight decrease in accuracy. Further decomposition [16,31] does not significantly reduce computation as the depthwise convolution computation is already minimal.
3.2-Network Structure and Training
Except for the first layer, which is a standard convolution, MobileNet’s structure is based on depthwise separable convolution. The entire network structure is shown below: 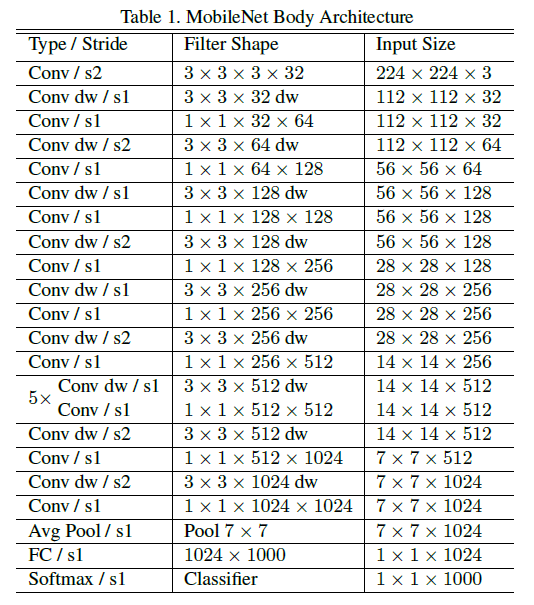
It’s worth noting that a small number of Mult-Adds does not necessarily mean the model is efficient. Efficient implementation of these Mult-Adds operations is equally important. For example, unstructured sparse matrix operations are not necessarily faster than dense matrix operations unless sparsity is very high. Our model converts almost all computations into dense 1x1 convolution operations, which can be implemented using highly optimized general matrix multiplication (GEMM). Typical GEMM-implemented convolution operations require im2col to reorder inputs in memory, which can be done using Caffe. Our 1x1 convolution can directly apply the GEMM algorithm (one of the best numerical linear algebra algorithms) without reordering. In MobileNet, 95% of Mult-Adds operations and 75% of parameters come from 1x1 convolution.
Training details: TensorFlow + RMSprop + asynchronous gradient descent (similar to InceptionV3) + less regularization and data augmentation (small models are less prone to overfitting) + little or no weight decay on the depthwise filters (as they already have few parameters).
3.3-Width Multiplier: Thinner Models
Although the current MobileNet is already small and fast, even smaller models are sometimes needed. We introduce a hyperparameter (width multiplier) to build these smaller models. This parameter aims to uniformly reduce the entire network at each layer. Given , the input channel number M becomes , and the output channel number N becomes . The typical values for are 1, 0.75, 0.5, 0.25. The computation cost after using this parameter is:
The computation cost is approximately reduced to of the original.
3.4-Resolution Multiplier: Reduced Representation
The second hyperparameter to reduce network computation is (resolution multiplier), set by adjusting the input resolution, which subsequently reduces the internal resolution. The computation cost after adding hyperparameters becomes:
Typically, the resolution set by is 224, 192, 160, 128. Note that setting this parameter changes the computation cost but not the model parameters.
4-Experiments
This section discusses several experiments, starting with a comparison between depthwise separable convolution and standard convolution, and between thin and shallow MobileNet. It then introduces the experimental results of the two hyperparameters, including ImageNet accuracy, the number of Multi-Adds operations, and the number of parameters. Finally, it presents MobileNet’s experimental results on various applications (fine-grained classification, large-scale geolocation, facial attributes, object detection, face embeddings).
4.1-Model Choices
Experimental results show that the fully convolutional MobileNet and depthwise separable convolution have similar accuracy, but depthwise separable convolution has significantly fewer parameters and computation. Compared to shallow MobileNet, thin MobileNet achieves higher accuracy with similar computation. Experimental results are shown below: 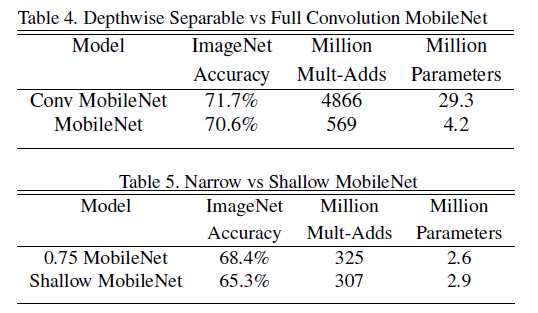
4.2-Model Shrinking Hyperparameters
This section discusses the tuning of the two hyperparameters mentioned above, with experimental results shown below: 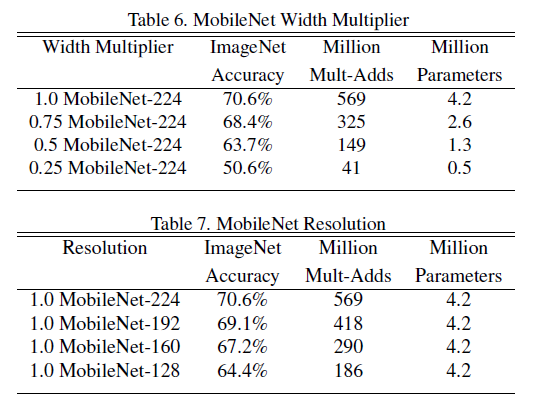
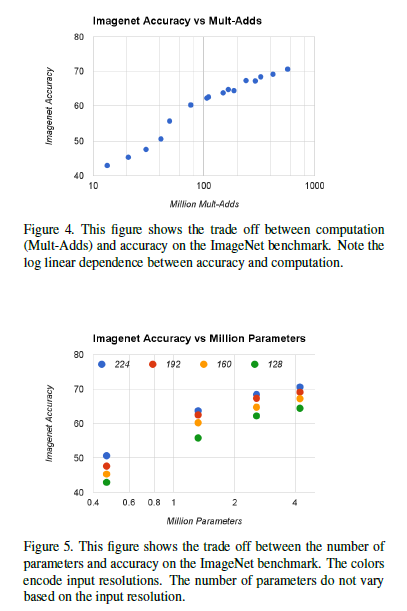
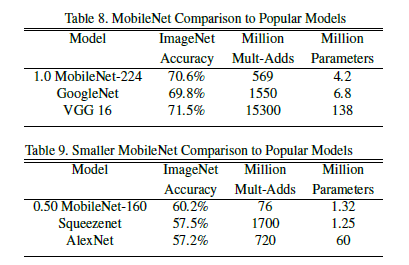
4.3-Fine Grained Recognition
Using the Stanford Dogs dataset and some noisy online data, a model for fine-grained classification was trained with good tuning. It achieved near state-of-the-art results while reducing computation and model size. Experimental results are shown below: 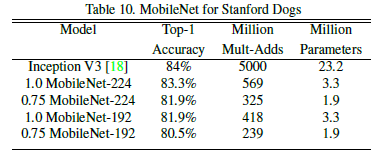
4.4-Large Scale Geolocalizaton
PlaNet addresses the geolocation problem by converting it into a classification problem. PlaNet has successfully located many photos and outperformed Im2GPS on this issue. MobileNet structure was used to retrain PlaNet on the same data, with experimental results shown below: 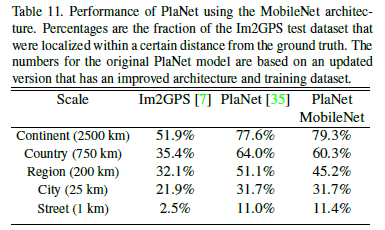
4.5-Face Attributes
MobileNet can also compress large-scale systems with unknown training processes. In a facial attribute classification system, MobileNet was used in conjunction with distillation. After combining the two, the system required no regularization and showed stronger performance. Experimental results are shown below: 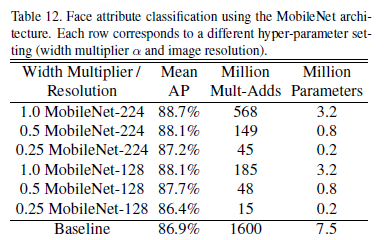
4.6-Object Detection
This experiment trained VGG, Inception, and MobileNet on SSD and Faster-RCNN using the COCO dataset, with results shown below: 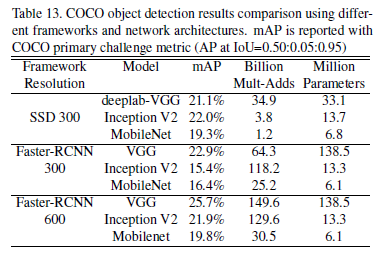
4.7-Face Embeddings
FaceNet is the state-of-the-art result for Face Embedding. Here, distillation was also used to train Mobile FaceNet. Results are shown below: 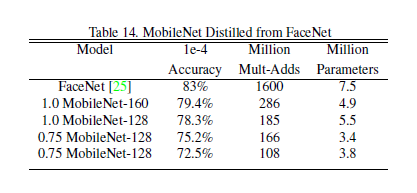
5-Conclusion
A model structure based on depthwise separable convolution was proposed, using width multiplier and resolution multiplier hyperparameters to control model complexity. Comparisons in model size, speed, and accuracy with other models demonstrated MobileNet’s efficiency across various applications. Future work aims to improve and further develop MobileNet.
6-Additional Related Summaries
Datasets: ImageNet (image classification), Stanford Dogs dataset (fine-grained classification), YFCC100M (facial attributes), COCO (object detection)
Related Papers:
Datasets
”Imagenet large scale visual recognition challenge” (ImageNet, ILSVRC 2012)
“In First Workshop on Fine-Grained Visual Categorization” (Stanford Dogs dataset)
“Yfcc100m: The new data in multimedia research” (YFCC100M)
Deeper and More Complex High-Accuracy Neural Networks
”Inception-v4, inception-resnet and the impact of residual connections on learning” (InceptionV4)
“Rethinking the inception architecture for computer vision” (InceptionV3, additional spatial decomposition)
“Deep residual learning for image recognition” (resnet)
“Going deeper with convolutions” (GoogleNet)
“Very deep convolutional networks for large-scale image recognition” (VGG16)
“Imagenet classification with deep convolutional neural networks” (AlexNet)
Compression and Acceleration of Neural Networks
”Flattened convolutional neural networks for feedforward acceleration” (additional spatial decomposition)
“Factorized convolutional neural networks” (convolution decomposition)
“Squeezenet: Alexnet-level accuracy with 50x fewer parameters and <1mb model size” (using bottleneck for small networks)
“Quantized convolutional neural networks for mobile devices” (compression based on product quantization)
“Xnornet: Imagenet classification using binary convolutional neural networks” (using low bit networks)
“Training deep neural networks with low precision multiplications” (using low bit networks)
“Quantized neural networks: Training neural networks with low precision weights and activations” (using low bit networks)
“Xception: Deep learning with depthwise separable convolutions” (scaling depthwise separable filters)
“Structured transforms for small-footprint deep learning” (networks for reducing computation)
“Deep fried convnets” (networks for reducing computation)
“Compressing neural networks with the hashing trick” (compressing neural networks using hashing)
“Rigid-motion scattering for image classification” (initial proposal to decompose standard convolution into depthwise conv and 1x1 conv)
“Deep compression: Compressing deep neural network with pruning, trained quantization and huffman coding” (compressing networks using Huffman coding)
“Speeding up convolutional neural networks with low rank expansions” (additional variable decomposition)
“Speeding-up convolutional neural networks using fine-tuned cp-decomposition” (additional variable decomposition)
“Distilling the knowledge in a neural network” (using distillation to train small networks from large networks for compression)
BN
”Batch normalization: Accelerating deep network training by reducing internal covariate shift” (InceptionV2 also derived from this)
Frameworks
”Caffe: Convolutional architecture for fast feature embedding"
"Tensorflow: Large-scale machine learning on heterogeneous systems”
Image Localization
”IM2GPS: estimating geographic information from a single image” (proposed Im2GPS)
“Large-Scale Image Geolocalization” (about Im2GPS)
“PlaNet - Photo Geolocation with Convolutional Neural Networks” (PlaNet)
Fine-Grained Classification
”The unreasonable effectiveness of noisy data for fine-grained recognition”
Object Detection
”Faster r-cnn: Towards real-time object detection with region proposal networks” (Faster-RCNN framework)
“Ssd: Single shot multibox detector” (SSD framework)
Face Embeddings
”Facenet: A unified embedding for face recognition and clustering” (FaceNet, constructing face embeddings based on triplet loss)